파이썬에서 제공하는 4개의 자료구조 타입
자료구조란 여러개의 값들을 모아서 관리하는 데이터 타입을 의미한다.
List, Tuple
여러 값을 순서로 식별 가능
list : 순서 o, 중복 가능, 원소 변경 가능
Tuple : 순서 x, 중복 가능, 원소 변경 불가
Dictionary, Set
여러 값을 순서로 식별할 수 없음
예) 홍길동(이름), 20(나이), 서울(주소) - 한 사람의 정보임, 같은 종류의 정보 x이므로 순서로 식별x
Dictionary : 순서 x, key-value형태, value는 중복된 값을 저장가능 그러나 key는 중복될 수 없음
Set : 순서 x, 핵심은 중복을 허용하지 않는다는 것, 집합의 개념
- len(자료구조) 함수 :
문자열에서는 글자수를, 자료구조에서는 값들의 개수를 세어줌
자료구조 변환함수
- list(자료구조)
- tuple(자료구조)
- set(자료구조)
- 대상 자료구조/Iterable을 Set으로 변환
- 다른 자료구조의 원소 중 중복을 빼고 조회
- Dictionary로 변환하는 함수는 없다.
- 변경할 대상이 Dictionary일 경우에는 Key값들만 모아서 변환
t =(1, 2, 3, 4, 5)
#t에 100을 추가 : tuple -> list로 변환 후 값추가 -> tuple
l = list(t)
l.append(100)
t = tuple(l)
list("안녕하세요.") #문자열 : 문자를 모아놓은 iterable
> ['안', '녕', '하', '세', '요', '.']
r = "배 사과 귤 수박 복숭아".split() #띄어쓰기 기준으로 분할
> ['배', '사과', '귤', '수박', '복숭아']
"-".join(r)
#"합칠 때 사용할 구분문자열".join(리스트) -> 리스트이 문자열 원소들을 하나의 문자열로 합친다
>'배-사과-귤-수박-복숭아'1. LIST
- 값을 순서를 이용해 식별하여 관리하는 자료구조
- 리스트는 순서가 중요하다. 각 원소의 순번을 index라고 한다.
- 값을 조회, 변경 할 때 이용/양수 , 음수 index 존재- 문자열처럼 값을 모아두면 인덱스가 자동으로 부여됨
- 리스트를 구성하는 원소들은 새로 추가하거나 변수에 값을 넣을 때, 순서대로 넣어야함
예: person_info = ['홍길동',20,"서울",178.2,82.54,"A"]
이름을 조회 > person_info[0] :0번 인덱스를 조회
다른 사람들의 정보도 이름,나이,지역,키,몸무게,혈액형 순으로 등록
- 중복된 값 저장 가능
- 각 원소들의 데이터 타입 달라도 됨.(보통은 같은 타입 이용)
- 원소 변경 가능 (추가, 삭제, 변경), tuple은 불가능
- #생성 l1 = [10,20,30,40,50,10,10,10] # 다른 타입의 값들을 모을 수 있다(일반적인 경우는 x) l2 = ["a",20,1.2,True]
Indexing과 Slicing을 이용한 원소(element) 조회 및 변경
indexing 리스트에서 원소(값) 한개만 조회,변경
slicing 범위로 조회하거나 그 범위의 값들을 변경
Indexing
- 하나의 원소를 조회하거나 변경할 때 사용
- index의 원소를 조회 : 리스트[index]
- index의 원소를 변경 : 리스트[index] = 값
- 삭제 : del 리스트[index]
- 추가 : .append() - 마지막 index에 원소를 추가
#조회
l1 = [10,20,30,40,50,10,10,10]
l1[0],l1[-8] -> 10 10
l1[4],l1[-4] -> 50 50
#변경
l1[0] = 1000
l1 > [1000, 20, 30, 40, 50, 10, 10, 10]
#삭제
del l1[1] #삭제 후 index가 앞으로 땡겨짐(index는 빈 값이 x)
#추가
l1.append(10000)
l1 > [1000, 20, 30, 40, 50, 10, 10, 10,10000]
Slicing
- 범위로 조회하거나 그 범위의 값들을 변경
범위 조회
- 리스트 [시작 index : 종료 index(포함x) : 간격]
#조회
리스트 [ : 5] => 0 ~ 4 까지 조회
리스트[2 : ] => 2번 index 에서 끝까지
##명시적으로 간격을 줄 경우
리스트[ : : 3 ] => 0, 3, 6, 9.. index의 값 조회
리스트[1 : 9 : 2] => 1, 3, 5, 7 index의 값 조회
##시작 index > 종료 index, **간격 음수 : 역으로 반환
리스트[5: 1: -1] => 5, 4, 3, 2 index의 값 조회
리스트[: : -1] => 마지막 index ~ 0번 index(reverse)
l2 = [0,1,2,3,4,5,6,7,8,9]
l2[1:8:3] -> [1,4,7] #인덱스 1~7까지 조회, 간격 3 -> 1+3=4, 4+3 = 7
l2[2::2] > [2,4,6,8] # 2 ~ 끝, 간격 :2
l2[1:-1] > [1,2,3,4,5,6,7,8] # 1~끝에서 2번째
범위 변경
- 리스트[시작 : 종료] = 원소
- 리스트[1:5] = 10,20,30,40 : index 1, 2, 3, 4의 값을 각각 10, 20, 30, 40 으로 변경
- slicing 을 이용할 경우 slicing된 원소 개수와 동일한 개수의 값들을 대입한다.
#변경
l2 = [0,1,2,3,4,5,6,7,8,9]
l2[2:5] = 20,30,40 # 2~4 원소 변경
l2 > [0,1,20,30,40,5,6,7,8,9]
## 뒷 부분 전부 변경 : 리스트[시작:]
l2[6:] =[1000]
l2 > 0,1,2,3,4,5,1000
리스트 연산자
l1 = [1,2,3]
l2 = [100, 200, 300, 400]
#두 리스트의 값을 합친 새로운 리스트를 생성
l3 = l1 + l2
l3
# l1 안에 1또는 2가 있는지?
#따로 물어본 후 and, or로 묶어줘야함
1 in l1 or 2 in l1 > True
# l1 안에 1과 2가 모두 있는지?
1 in l1 and 2 in l1 > True중첩리스트 : 원소로 list를 가지는 것
#리스트 안의 리스트
#리스트 안에 튜플, 딕셔너리 등 넣을 수 있는데 중첩 리스트는 리스트가 들어간 경우
l1 = [1,2,3]
l2 = ['가','나','다','라']
l3 = [l1, l2]
l3 > [[1, 2, 3], ['가', '나', '다', '라']]
#2를 조회
#박스 안의 박스는 순서가 생김
#[[1,2,3]:0번 박스 ,[가,나,다,라]:1번 박스]:큰 박스 #리스트를 2번써야함
l3 = [[1, 2, 3], ['가', '나', '다', '라']]
l3[0][1] > 2
#1번 박스의 1~끝 조회 - list조회
l3[1][1:] > l3 > [[1, 2, 3], ['가', '나', '다', '라']]List 대입(리스트 대입)
#리스트의 원소들을 다른 변수에 대입
v1, v2, v3 = [10,20,30] #변수의 개수와 리스트 원소의 개수는 동일
print(v1,v2,v3)
#튜플 대입
v11, v22, v33 = 1,2,3 #소괄호 생략가능 (1,2,3)List 주요 매소드
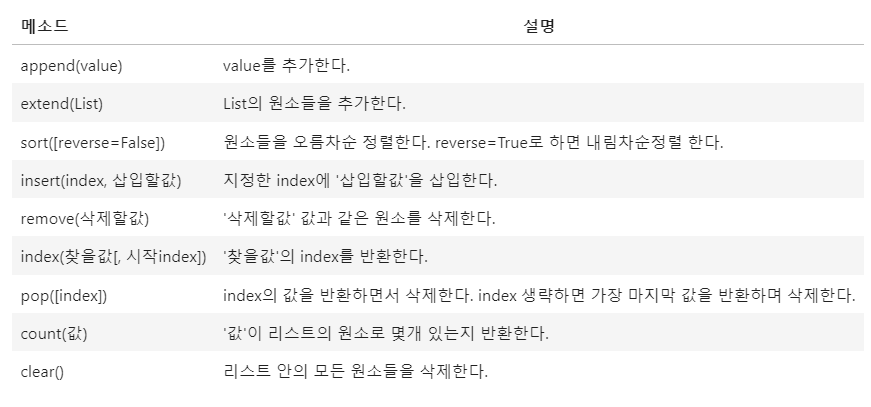
l = [1,2,3,4,5,6,7]
#조회
index[찾을값의 index]
count(값) : 원소로 몇개 있는지 반환
#추가
append() #값 1개 추가
extend() #리스트 안의 값 여러개 추가
insert(index, 값) #중간에 추가
l.append(10) #10을 추가 => l(리스트)에 바로 추가.
l.extend([100,200,300]) #list의 요소들를 추가
l.insert(3, 10000) #인덱스 3에 10000삽입 #insert 이후 값들은 한칸씩 밀린다
l.insert(20,11) #index에 없으면 append()가 된다.
#삭제
remove(값)
del 리스트[index]
pop([index])
clear()
l.remove(8) #remove는 값을 삭제, del은 인덱스로 삭제
del l[]
v2 = l.pop() #마지막 index의 값을 삭제하면서 반환
v2 > 7
l > [1,2,3,4,5,6]
l.clear() #모두 삭제
#정렬
l.sort() #l의 원소들을 오름차순 정렬
l.sort(reverse = True) #내림차순 정렬
# 정렬 함수 : sorted(자료구조) => 정렬 결과를 리스트로 반환.
l1 = sorted(l) #l을 바꾸는 것이 아니라 정렬한 결과를 새로운 리스트에 담아야함
sorted("가ABabc#!") #문자열은 한글자를 한 요소로 변환해 정렬
sorted("가Ababc#!", reverse = True) #내림차순 정렬
#리스트 초기화 후 값 순차적으로 추가 -> 반복문에서 자주 사용
results = [] # 빈리스트 초기화
results.append(1+1)
results.append(10*2)
results.append(100/5)
results
'■ Tools > Python' 카테고리의 다른 글
| [python] 03.자료구조 | Set (0) | 2023.10.24 |
|---|---|
| [python] 03.자료구조 | Dictionary (0) | 2023.10.24 |
| [python] 03.자료구조 | Tuple (1) | 2023.10.24 |
| [python] 01. python 변수 - 02. 데이터 타입 정리 | 변수/데이터 타입/문자열/형변환 (0) | 2023.10.24 |
| python 프로그래밍 개요 (0) | 2023.10.24 |

