딥러닝 모델 개선 방법
- Epoch 수와 과적합
- DNN 모델 크기 변경
- Dropout Layer 추가를 통한 Overfitting 규제
- Batch Normalization (배치정규화)
- Optimizer의 Learning rate(학습율) 조정을 통한 성능 향상
- Hyper parameter tuning
Dropout Layer 추가를 통한 Overfitting 규제
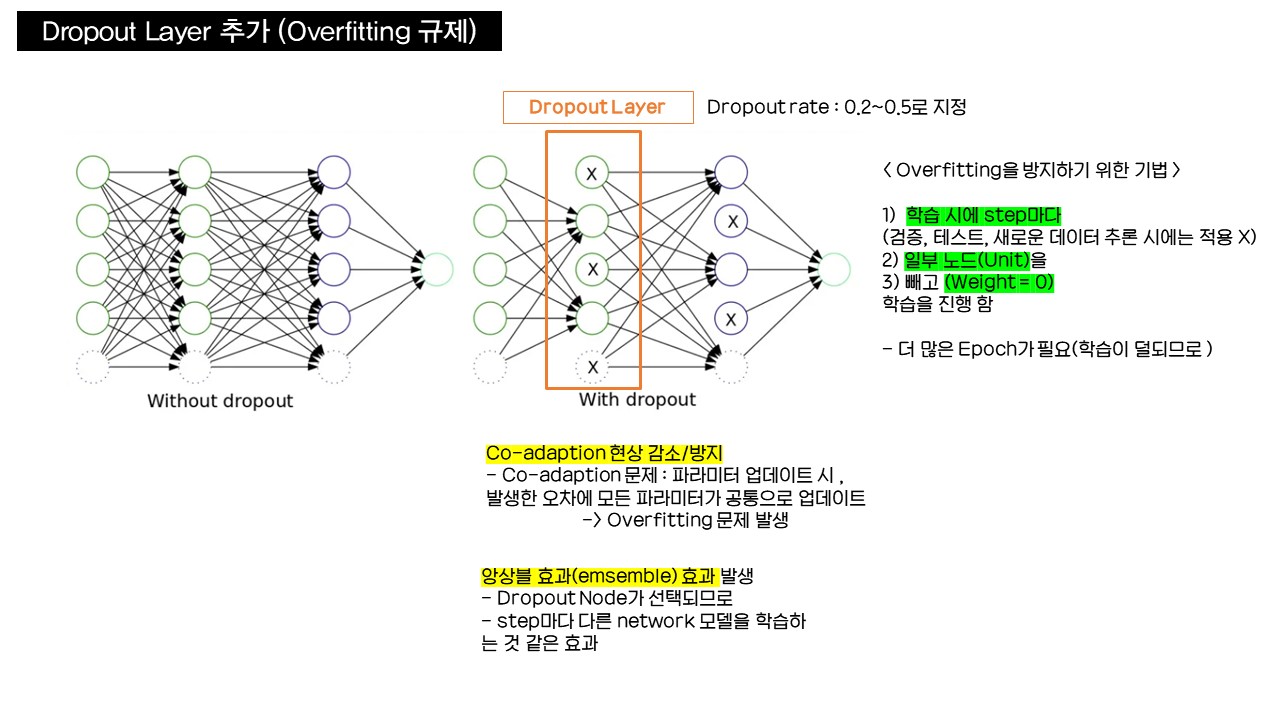
- Neural networkdml Overfitting을 방지하기 위한 기법
- 과대적합 Overfitting : 모델이 너무 복잡해서 발생 → Train dataset의 너무 많은 특성을 학습하여 데이터에 대한 일반성이 떨어짐
- 과대적합 Overfitting : 모델이 너무 복잡해서 발생 → Train dataset의 너무 많은 특성을 학습하여 데이터에 대한 일반성이 떨어짐
- Dropot Node
- 학습 시에 1) 일부 Unit(노드)들을 2)Random하게 3)빼고 학습함. (Weight → 0으로 만듦)
- 학습대상에서 빠지는 노드 : Dropout Node
- Dropout Node는 Weight = 0 인 상태에서 학습 / update 시, 최적화 대상에서 제외
- 매 Step 마다 Dropout node는 Random하게 바뀜
- Dropout 적용시 더 많은 Epoch필요 → 각 노드들이 학습이 적게 되어서 보완 필요
- 학습 시에만 적용 , 검증/테스트/새로운 데이터 추론 시에는 적용 X
- Dropout rate
- Dropout에 적용되는 Layer에서 전체node 대비 dropout node의 비율 : 보통 0.2~0.5
- 너무 크게 지정 → 과소적합underfitting 발생
- Dropout의 효과 : overfitting의 원인인 co-adaption현상을 감소/방지함
- co-adaption현상
- 각 Node의 모든 파라미터들이 업데이트 되면서, 발생한 오차에 모든 파라미터가 공동책임으로 업데이트 되는 것 → 쓸데없는 패턴과 특성을 학습해 overfitting 발생
- 학습마다 Node를 랜덤으로 학습에서 제외하므로 co-adaption현상 방지 가능(일부 파라미터만 업데이트)
- 오차발생에 원인이 있는 파라미터만 선택하는 것이 최선이지만 이를 알 수 없으므로 임의 선택
- co-adaption현상
- Step마다(Dropout node가 선택되어 학습되므로) 다른 network 모델을 학습시키는 형태 → 앙상블(emsemble) 효과 발생
- Dropout 적용 : Dropout은 학습시에만 적용하고 검증, 테스트, 새로운 데이터 추론시에는 적용되지 않는다
Dropout 예제
- dropout 각 레이어에 적용
- dropout은 nn.Dropout 객체를 사용
- 객체 생성 시 dropout_rate 설정: 0.2 ~ 0.5
- Drop시킬 노드를 가진 Layer 뒤에 추가한다.
1. 모델 정의→ 2. 모델 객체 생성 → 3. 손실함수 정의+ 최적화 함수 정의→4. 학습(module.fit)
1. 모델 정의
모델에 drop_rate, Dropout 레이어를 설정한다.
Linear, Relu, Dropout레이어 순서로 배치하는것이 성능이 좋기 때문에 이렇게 적용했으나, 순서를 바꿔도 상관은 없다.
class DropoutModel(nn.Module):
def __init__(self, drop_rate=0.5):
super().__init__()
self.b1 = nn.Sequential(nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(p=drop_rate))
self.b2 = nn.Sequential(nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(p=drop_rate))
self.b3 = nn.Sequential(nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=drop_rate))
self.b4 = nn.Sequential(nn.Linear(128, 128),
nn.ReLU(),
nn.Dropout(p=drop_rate))
self.output = nn.Sequential(nn.Linear(128, 10),
nn.Dropout(p=drop_rate))
def forward(self, X):
out = nn.Flatten()(X)
out = self.b1(out)
out = self.b2(out)
out = self.b3(out)
out = self.b4(out)
out = self.output(out)
return out2. 모델 객체 생성
d_model = DropoutModel().to(device) # drop_rate=0.5(default)
torchinfo.summary(d_model, (BATCH_SIZE, 1, 28, 28))3. 모델 손실 함수, 최적화함수 + 4. 모델 학습
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(d_model.parameters(), lr=LR)
result = train.fit(train_loader, test_loader, d_model, loss_fn, optimizer,
N_EPOCH, save_best_model=False, early_stopping=False,
device=device, mode="multi")
'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| 딥러닝 모델 개선 | 5. Learning rate(학습율) 조정 (0) | 2023.10.30 |
|---|---|
| 딥러닝 모델 개선 | 4.Batch Normalization (배치정규화) (0) | 2023.10.30 |
| 딥러닝 모델 개선 | 2. DNN 모델의 크기를 변경하는 방법 (0) | 2023.10.30 |
| 딥러닝 모델 개선 | 1. Epoch수와 과적합 (0) | 2023.10.26 |
| 딥러닝 모델 성능 개선 | 과대적합과 과소적합의 문제 해결하기 (0) | 2023.10.26 |



