ImageNet Dataset
ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회
주요 CNN 모델
- VGGNet
- ResNet
- Mobilenet
VGGNet(VGG16)
모든 layer들에 3X3 filter, stride =1 , same padding의 Convolution Layer와 2x2, stride=2의 Max pooling사용 -> 단순한 구조로 레이어를 많이 쌓아 성능을 높임. 3X3 필터를 2개 쌓는 것이 적은 파라미터로 더 좋은 성능을 보임
VGG(Visual Geometry Group)
ImageNet ILSVRC Challenge 2014에서 2등한 모델, 구조가 간결하고 사용이 편리해 1등한 GoogleNet보다 각광받음
- 모든 layer들에 3X3 filter, stride =1 , same padding의 Convolution Layer와 2x2, stride=2의 Max pooling사용
- MAX Pooling 이용해서 Feature map사이즈를 줄임
- 단점 : 추론기에 Fully Connected Layer 3개가 붙어 파라미터가 너무 많아짐 (1억 4천만개 파라미터 중 1억 2천만개 - fully connected layer)
ResNet (Resdual Networks)
잔차모듈 (Residiual module) : skip connection이라는 layer를 획기적으로 쌓아 모델 성능을 높이는 구조가 사용됨
: 레이어를 깊게 쌓을 수록 네트워크 성능이 좋아지는데 최적화 문제 발생 가능, 레이어를 쌓는과정에서 Residual block을 이용해 입력받은 값에 조금씩 수정한 값을 더하면서 최적의 y를 찾는 것이 skip connection 이용하면 성능 유지됨
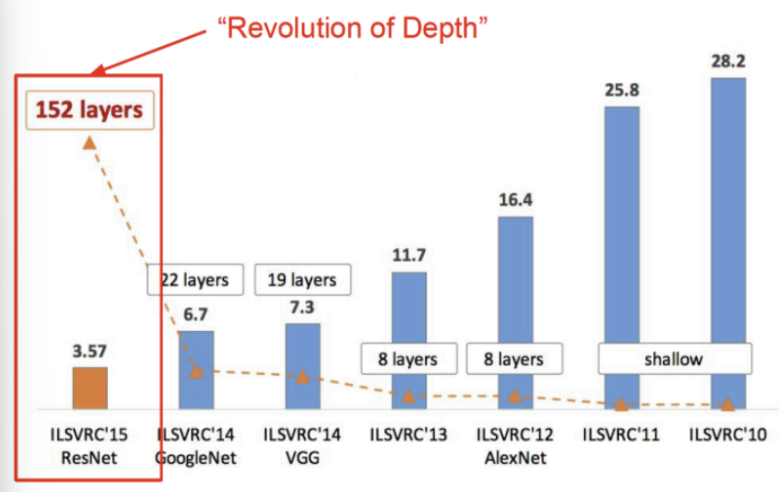
- 역사 : 딥러닝과 반대되는 shallow leanrning -> AlexNet은 파라미터가 있는 layer를 8개 사용함-> layer가 19개까지 올라갈 때는 성능이 좋아졌지만 21개부터는 오히려 성능이 좋지 않음 -> 레이어를 쌓는 것은 성능개선을 하지만 그렇지 않을때 존재
- Skip connection(Shortcut connection)기법을 이용해 Layer를 획기적으로 152개로 늘린 CNN모델 -> Skip connection기법은 최근에 거의 모든 모델에 사용됨
Skin connection의 구조에서 최적화문제 발생
레이어를 깊게 쌓으면 성능이 좋아지는 이유 : 비선형적이 추가되어 더 많은 특성들을 추출-> 네트워크 모델의 성능이 더 좋아짐
최적화 문제 발생 : 레이어를 깊게 쌓으면 weight를 많이 생성해 최적화가 안되어서 train에서도 성능이 나쁨 - overfitting(train에서는 성능이 좋음, test에서 나쁜 것)으로 정확도 개선이 어려워지는 건줄 알았는데 Test set + Train set에서도 성능이 나쁜 문제
최적화 문제 해결 : Residual block을 이용한다
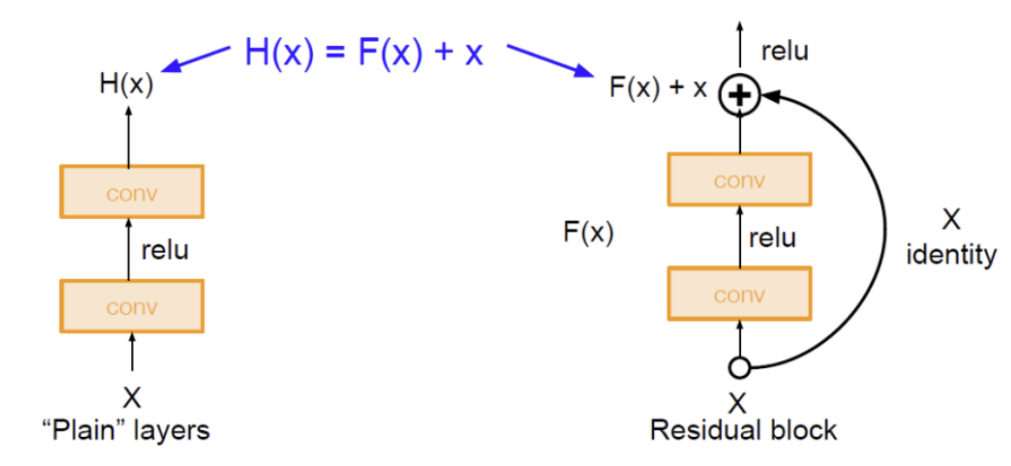
- ResNet의 Skip connection은 입력값 X를 레이어를 통과시켜서 나온 Y( Residual block )에 입력값 X를 더해서 합치도록 구성

- identity mapping (= skip connection = skipconnection)은 입력인 x를 직접 전달하는 연결( 입력값 그대로 출력하는 block : X 입력 -> return X ) , 이 논리를 사용하면 파라미터 없이 단순이 값을 더하는 구조이므로 연산량에 크게 영향 X
=> 따라서 성능이 떨어지지 않으면서 깊은 Layer를 쌓음
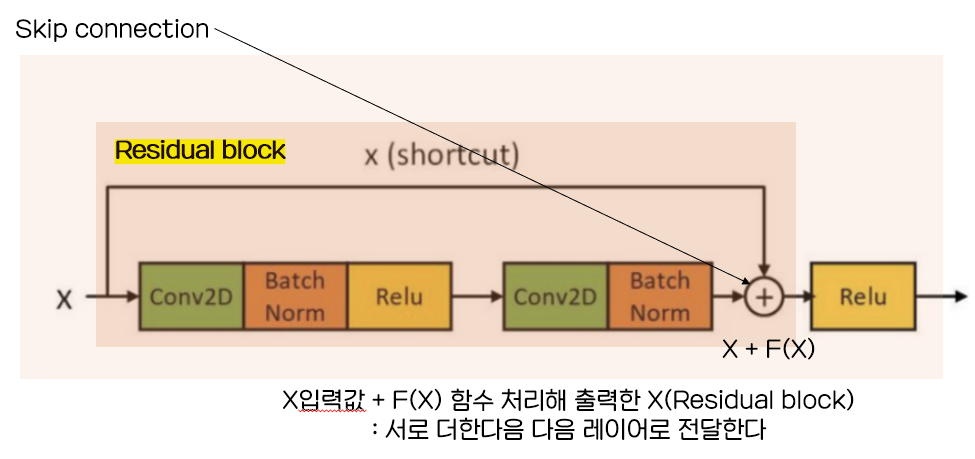
- 지금까지는 입력한 값에 연산처리를 한(convolution -> B/N-> Relu) 최종값만 출력했다면 , 여기서는 연산처리한 최종값 + 최초 입력값을 서로 더해서 출력한다.
- 입력받은 값을 바탕으로 최적의 y를 찾아내는 데, X조금씩 변화를 주면서 찾아나가는 과정이 잔차학습법이다.
Residual block을 통한 성능 향상
- H(x) = F(x) + x 을 x에 대해 미분하면 최소한 1이므로 Gradient Vanishing 문제를 해결함.
Residual block 구조
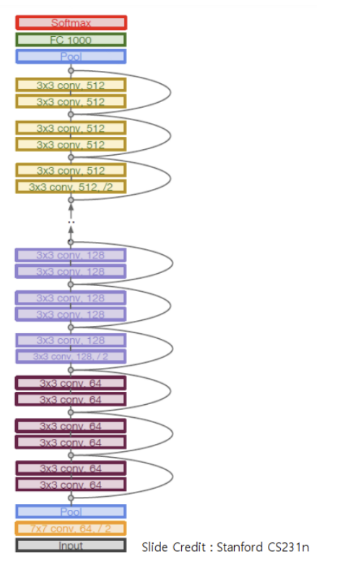
- 일반 Convolution layer(backbone)을 먼저 쌓고 Identity(residual) block들을 계속 쌓음
- 모든 Identity block은 두개의 3x3 conv layer로 구성
- 일정 레이어 수 별로 filler의 개수를 두배로 증가 시킴 -> stride를 2로 해서 downsampling함 (pooling layer는 identity block의 시작과 끝에만 적용)
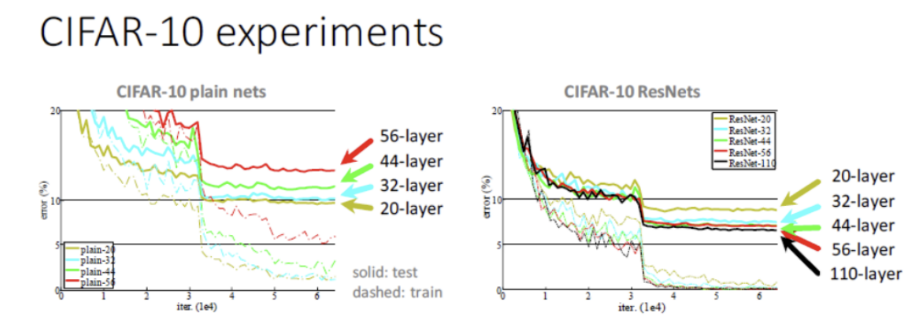
MobileNet
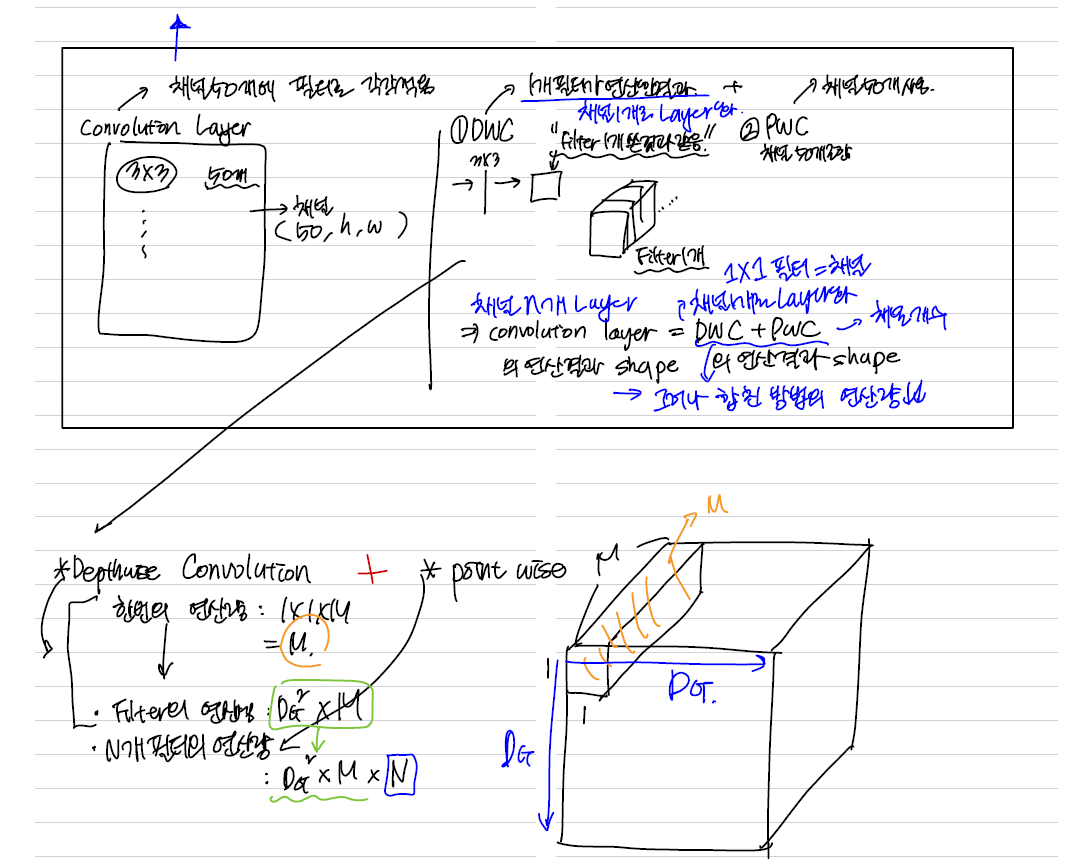
모델 경량화는 적은 연산량을 사용하면서, 모델의 크기도 줄이면서도 납득할 수 있는 성능을 가진 모델을 개발하는 것. Mobilenet 은 Channel Reduction- Distillation & Compression- Depthwise Seperable Convolution을 이용한 (채널 줄이고 , 두 레이어 연결해서 연산량 줄이고, 높은 모델에서 학습한 내용+중요하지않은 파라미터 손절하는 ) 경량 네트워크 모델. Depthwise convolution Layer 에서는 input shape( Df,Df,M) 에 대해서-> (Dk,Dk,1) shape 필터 M개 생성 하고 한개의 Filter는 한개의 Channel에만 Convolution 연산을 한하게만들어 M개의 channel에 대해서 Convolution 연산처리 를 한다 이후 Pointwise Convolution Layer에서는 (1,1,M) shape의 필터를 N개사용한 것을 곱해주는 연산을 한다. 이러면 shape은 똑같은데 연산량을 줄일 수 있음
이전에는 성능을 높이는 것만 신경썼다면, 가벼운 딥러닝 네트워크 = 경량 네트워크를 위한 연구가 활성화
- 경량화의 조건 = 적은 연산량으로 빠르게 추론할수있으되 , 납득할 수 있는 성능을 내야함
1) 적은 연산량(낮은 계산 복잡도)를 통한 빠른 실행
2) 적은 모델 크기
3) 충분히 납득할만한 정확도
4) 저전력사용
Small Deep Neural Network위한 방법
- Channel Reduction ( 채널 줄이기 )
- Distaillation ( 내리 학습 ) & Compression ( 중요하지 않은 파라미터 손절)
- Deptwise Seperable Convolution (두 레이어 Depthwise convolution & Pointwise Convolution 연결해서 연산량 줄이기)
- Remove Fully - Connected Layers
- Kernel Reduction ( kernel(filter)크기 줄임 - 연산량과 파라미터 수 줄임)
- Early Spaced Downsampling ( 최적의 downsampling하는 시점을 찾는 것 )
| Mobilenet 은 위의 방법중 3가지를 적용해 경량 네트워크 모델
- Channel Reduction
- Distillation & Compression
- Depthwise Seperable Convolution
< Deptwise Seperable Convolution >
- 두 레이어 Depthwise convolution & Pointwise Convolution 연결해서 연산량을 줄인다
1) Depthwise convolution Layer : input shape( Df,Df,M) 에 대해서-> (Dk,Dk,1) shape 필터 M개 생성 -> ⭐한개의 Filter는 한개의 Channel에만 Convolution 연산을 한다 : M개의 channel에 대해서 Convolution 연산처리 ⭐
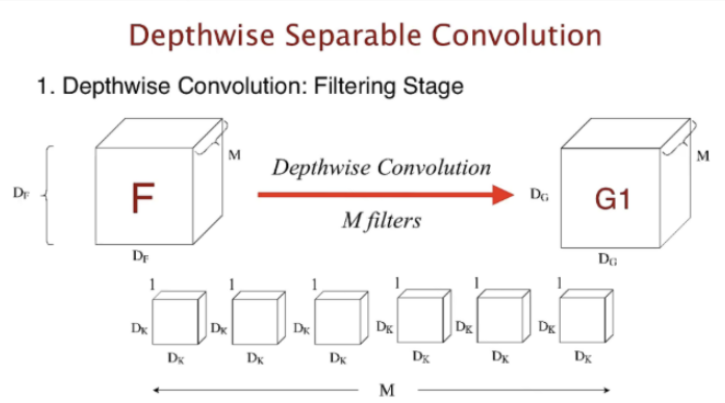
- 기존의 convolution layer에서 filter(1 * H *W) 1개가 layer가 된다
- 기존의 convolutional 에서는 conv2d( 3 - 채널, 5 - filter 5개, ...) -> 채널 3개인 필터가 5개 생성됨 그러나 DSC에서는 채널이 1개인 필터가 생성이 되는, 측 채널만큼의 필터가 생성되어 레이어를 구성하는 convolution layer임. -> 필터수가 다음 layer의 채널이 됨.
2) ⭐Pointwise Convolution Layer- 사이즈는 유지하면서 channel을 줄임 - 1X1을 가지는 레이어 => (1,1,M) shape의 필터를 N개사용
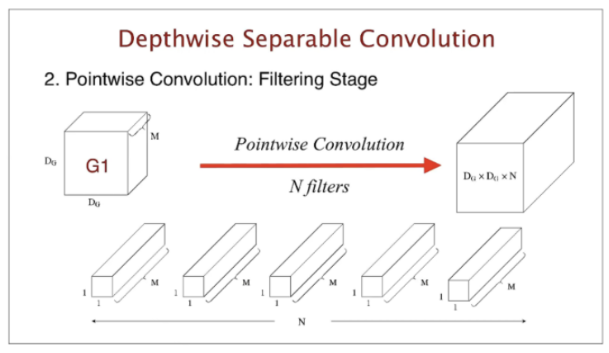
< 표준 Convolution 과 연산량 비교 >
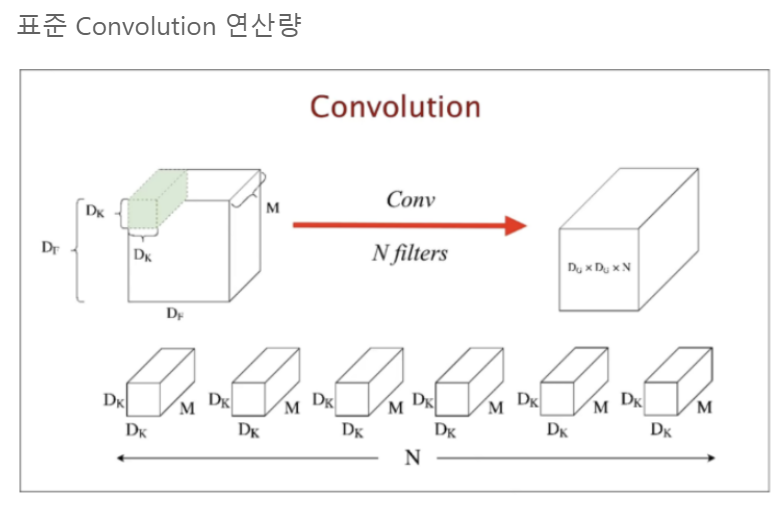



표준Convolution layer는 한번의 연산량이 Dk^2 X M( 필터의 개수) 이며, 하나의 필터는 Dg^2만큼 이동한다
그러나 DSC는 (Dk,Dk,1) shape 필터 즉, 필터 1개(1X1 shape)가 하나의 채널에 대응하는 연산을 먼저 실행한후 -> 필터의 개수를 곱해주는 연산을 진행하므로 , 한번의 연산량은 Dk^2이며 Dg^2만큼 이동한다 -> Point wise의 연산에서 M을 곱해준다. Dg^2만큼 이동하는 것도 포함해준다.




> 0.1120876736111111
'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| LSTM 주가예측 | 삼성전자의 주가(시계열데이터)를 예측해보자 (0) | 2023.11.04 |
|---|---|
| RNN 개요 | RNN (1) | 2023.11.01 |
| Pretrained Model | 2. Transfer Learning(전이학습)과 Fine tuning을 사용하자 (0) | 2023.10.31 |
| Image Augmentation | 1. 이미지에 효과를 주어 CNN small datasets의 데이터를 늘려보자 (0) | 2023.10.31 |
| 딥러닝 모델 개선 | 6. Hyper parameter tuning (0) | 2023.10.30 |


