
Sequential 데이터란
- 데이터의 순서 정보가 중요한 데이터셋으로 순서가 달라질 경우 의미가 바뀌거나 손상되는 데이터를 말한다.
- 예
- 자연어 텍스트
- 일정한 주기로 샘플링된 영상, 음성
- 시계열(time series) 데이터 :순서 + 데이터가 발생한 시점 정보가 중요한 데이터셋
RNN (Recurrent Neural Network) 구조
- RNN은 Feature 추출기로 Recurrent Layer을 사용하는 딥러닝 모델을 말한다..
- Recurrent Layer는 sequential 데이터 처리에 좋은 성능을 낸다.

Recurrent Layer 구조
- RNN은 순서대로 입력되는 데이터를 반복 처리하는 Recurrent Layer를 이용해 Feature vector를 추출하고+
그 Feature vector를 Estimator Layer에 전달해 추론한다.
- DNN, CNN은 순서를 고려하지 않고 특성 추출과 추론을 한다.
그 Feature vector를 Estimator Layer에 전달해 추론한다.
- DNN, CNN은 순서를 고려하지 않고 특성 추출과 추론을 한다.
메모리 시스템(Memory system)
- Sequential 데이터는 단순히 순서대로 처리하는 것 뿐만 아니라 이전 단계의 처리결과를 기억 = Memory 하고 그것을 현재 단계 처리에 사용한다.
- time step : Sequential 데이터 처리에서 순서대로 처리할 때 각각의 단계
- 예를 들어 4일간의 주가 변화로 5일째 주가를 예측하려면 입력받은 4일간의 주가를 순서를 기억하고 있어야 한다.
- Fully Connected Layer나 Convolution Layer의 출력은 이전 Data에 대한 처리와 상관없이 현재 데이터를 기준으로만 특성을 추출한다.
Simple RNN구조


wx : "x의 가중치" , wh :"h의 가중치" , b = w1, w2,w3
def RNN(X: "현재데이터", h:"이전처리"):
return tanh(X@wx + h@wh + b)
hidden = 0 #이전처리데이터가 누적
for i in range(10) # range가 제공하는 값이 현재순서의 값
hidden = RNN (i, hidden)문제 유형별 RNN 구조

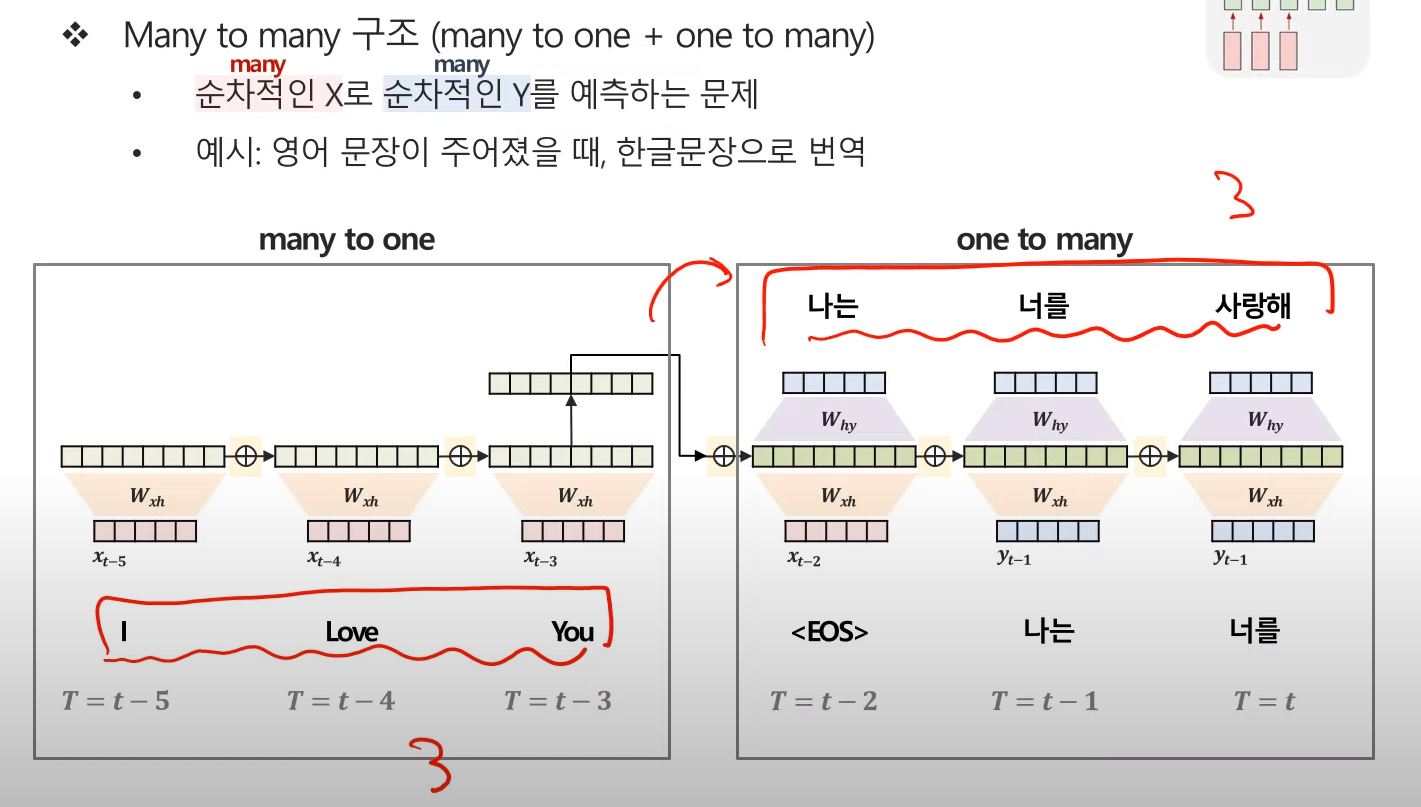
seq2Seq :

텍스트 분류 (Text classification)
- 입력받은 문장을 분류하는 문제 - 대표적으로 감성분석(semetic analysis)
- 감성분석 리뷰데이터 등에서 감성을 긍/부정을 분류하는 문제
Image captionning
객체명인식 (Named Entity Recognition)
- 토큰화된 단어가 어떤 종류,의미 인지 찾는 문제
예 : 미국에 사는 톰은 스무살 입니다 => 미국 : 위치, 톰 : 이름 , 스무살 : 나이
품사 태깅(Pos tagging)
- 각 토큰의 품사를 찾는 문제
예 : 미국에 사는 톰은 스무살 입니다 => 미국 : 대명사, 에 : 조사 , 은 :조사, 스무: 명사, 살: 명사 ,이다 :동사
Chatbot
- 입력 받은 문장에 대한 답을 하는 시스템
encoder는 질문을 받아 처리 , decoder는 답변을 생성
Machine translation
- 번역 시스템
- encoder는 번역 대상문장을 입력받아 처리하고 decoder는 번역문장을 생성
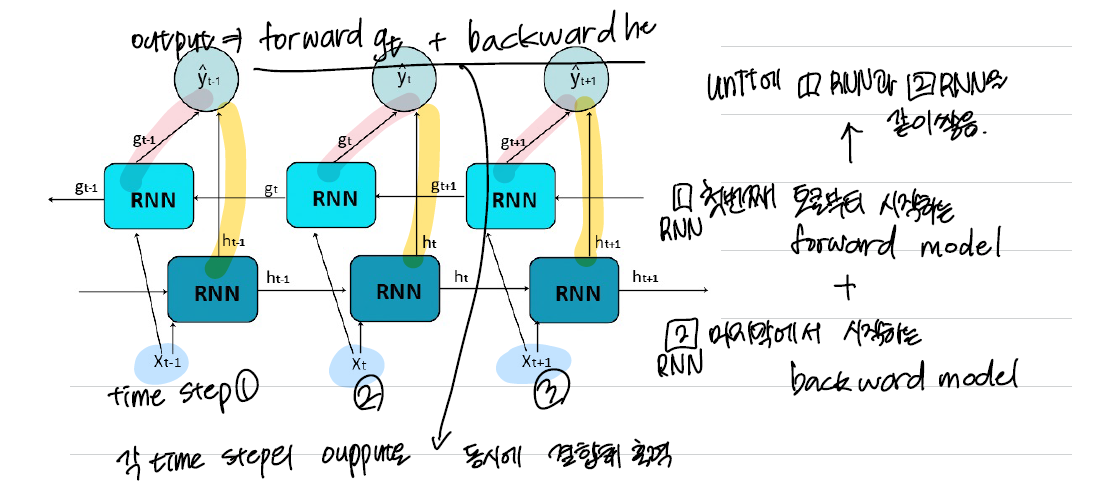
< Bidirectional RNN + Stacking(Multi Layer) RNN >
Bidirectional RNN

Auto Regressive 모델
이전 time step에 대한 출력결과를 다음 time step의 입력으로 사용하는 구조.
예 : Text 생성 모델
이전 출력의 결과에 의존하기 때문에 bidirectional RNN을 사용할 수 없다.
=> 왜? Non Auto Regressive 모델은 현재의 상태가 앞/뒤 상태에 따라 정해지는 경우로 앞/뒤의 상태를 모두 참조할 경우 성능이 올라가는 경우
Stacking(Multi Layer) RNN

- Recurrent Layer를 쌓아 모델의 용량을 늘려 표현능력(Represenational capacity)를 증가시킨다.
- 여러층을 쌓은 경우 먼저 쌓은 layer의 모든 time step별 출력이 다음 Layer의 입력 데이터로 사용된다.
- Layer을 쌓으면 표현능력은 증가하는 대신 계산 비용이 많이들고 과대적합(Overfitting)이 발생할 수 있다.
- 과대적합을 막기 위해 드롭아웃 레이어를 추가할 수있다.
- Recurrent Layer에서 Dropout layer는 매 time step 마다 적용한다.
Pytorch RNN Layer ⭐⭐⭐
input_size: 입력 데이터의 shape
hidden_size: Layer의 Hidden size
num_layers: 몇층으로 Layer을 쌓을지 개수
nonlinearity: 활성함수로 'tanh' (Default), 'relu' 둘 중 하나 지정.
batch_first: True - (batch, seqence len, ..) False - (sequence len, batch, ..). Default: False
dropout: Dropout rate 비율
bidirectional: 양방향 적용 여부. Default: False
CLASS torch.nn.RNN(self, input_size, hidden_size, num_layers=1,
nonlinearity='tanh', bias=True, batch_first=False,
dropout=0.0, bidirectional=False, device=None, dtype=None)hidden size를 2로 설정 -> 입력데이터가 dim이 4였어도 output은 2로 반환

RNN Layer의 input / output tensor 의 shape
1) 추론시 Input : Input_Data, Hidden_state
1) Input_data의 shape
- (Sequence_legnth, batch_size, feature_shape)
- pytorch 는 입력으로 batch 보다 sequence length가 먼저 온다.
- batch_first=True 로 설정하면 (batch_size, seq_len, feature_shape) 순이 된다.
- ex) 주가 데이터
- feature: 시가, 종가, 최고가, 최저가
- sequence: 100일치
- batch size: 30
- (100, 30, 4)

2) Hidden_state의 shape
- 시작(초기) hidden state로 입력하지 않으면 0이 들어간다.
- shape은 아래 hidden state 설명 참조
2) Output : (output_data, hidden_state)
- output_data과 hidden state를 tuple로 묶어서 반환한다.

1) Output shape
- (Sequence length, batch_size, hidden_size * D)
- D: 2 if bidirectional else 1
- batch_first=True 로 설정하면 (**batch_size**, seq_len, feature_shape) 순이 된다.
- ex)
- RNN Layer의 hidden size가 256 인 경우. (sequence length: 100, batch size: 30, bidirection=False)
- (100, 30, 256)
2) Hidden state
- 마지막 time step의 출력결과
- (D * layer수, batch_size, hidden_size)
- D: 2 if bidirectional else 1
- layer수: multi layer일 경우 layer stack 수
RNN의 Back Propagation
- BPTT(Back Propagation Through Time) 이라고 한다.
- RNN이 sequential하기 때문에 발생하는 hidden state를 따라 역행하면서 전파되는 gradient의 계산 방법이다.


RNN 파라미터 학습과정

🔗참고영상 : RNN, LSTM, GRU
'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| GAN 개념 | 진짜와 구별이 안되는 Generator 모델 (0) | 2023.11.04 |
|---|---|
| LSTM 주가예측 | 삼성전자의 주가(시계열데이터)를 예측해보자 (0) | 2023.11.04 |
| 주요 CNN 모델 | VGGNet , ResNet , Mobilenet (1) | 2023.11.01 |
| Pretrained Model | 2. Transfer Learning(전이학습)과 Fine tuning을 사용하자 (0) | 2023.10.31 |
| Image Augmentation | 1. 이미지에 효과를 주어 CNN small datasets의 데이터를 늘려보자 (0) | 2023.10.31 |


