Convolutional Layer 를 이용한 GAN 이미지 생성 모델
라이브러리 import
import os
import random
import time
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
Random Seed , device 설정
# Random Seed 설정 => 코드에서 사용하는 랜덤값을 생성하는 모든 lib에 설정.
seed_value = 0
random.seed(seed_value)
torch.manual_seed(seed_value)
np.random.seed(seed_value)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
하이퍼파라미터 변수 정의
dataroot: 학습데이터셋 저장 디렉토리 경로
workers: DataLoader로 데이터를 로드하기 위한 쓰레드 개수.
batch_size: 배치 크기. DCGAN 논문에서는 128의 배치 크기를 사용.
image_size: 훈련에 사용되는 이미지의 크기. 여기서는 64 X 64 사용.
nc: 입력 이미지의 컬러 채널 수. 컬러일 경우 3.
nz: Latent vector 의 길이. Fake 이미지를 만들때 입력할 데이터.
ngf: 제너레이터의 레이어들을 통과한 특징 맵크기의 기본값으로 레이어 별로 이 값에 * N한 값을 out features로 설정.
ndf: 판별기의 레이어들을 통과한 특징 맵크기의 기본값으로 레이어 별로 이 값에 * N한 값을 out features로 설정.
num_epochs: Train 에폭 수. 더 오래 훈련할수록 더 나은 결과를 얻을 수 있지만 시간도 훨씬 더 오래 걸린다.
lr: 훈련에 대한 학습률. DCGAN 논문에서 0.0002를 사용.
beta1: 아담 옵티마이저를 위한 베타1 하이퍼파라미터. 논문에서 0.5를 사용.
ngpu: 사용 가능한 GPU 개수. 0이면 CPU 모드에서 실행되고 0보다 크면 해당 수의 GPU에서 실행된다.
# 하이퍼파라미터 변수 설정
dataroot = r"datasets/celaba" # train dataset을 저장할 디렉토리
os.makedirs(dataroot, exist_ok=True)
workers = os.cpu_count() # DataLoader 사용. Data load시 사용할 thread 개수
batch_size = 128
image_size = 64 # 학습 이미지의 h, w 크기.
nc = 3 # 채널 수
nz = 100 # Latent vector의 크기. -> Generator의 입력 데이터(표준분포를 따르는 random 값들로 구성.)
ngf = 64 # G(enerative-생성자) 출력 F(eature map) 개수 설정에 사용할 값
ndf = 64 # D(iscriminator-판별자) 출력 F(eature map) 개수 설정에 사용할 값
num_epochs = 10
lr = 0.0002
beta1 = 0.5 # Adam 옵티마이저의 하이퍼파라미터
ngpu = 1 if device == 'cuda' else 0
학습 데이터셋 - celeb-A face dataset
- 유명인사들의 얼굴 사진들
- torchvision의 built-in dataset으로 받을 수 있다.
- https://pytorch.org/vision/stable/generated/torchvision.datasets.CelebA.html#torchvision.datasets.CelebA - 다음 사이트에서도 다운로드 받을 수 있다.
- http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- 다운 받은 뒤 압축을 풀면 디렉토리구조가 다음과 같다.
- 이것을 ImageFolder 를 이용해 Dataset으로 구성할 수 있다.
이미지파일 다운로드
## Built-in
########################################################################################
# Google Drive에서 다운 받는데 다운 횟수 limit가 있어서 못 받을 수 있다.
########################################################################################
# dataset = datasets.CelebA(root=dataroot, split="all", target_type=["attr", "identity"], download=True,
# transform=transforms.Compose([
# transforms.Resize(image_size),
# transforms.CenterCrop(image_size),
# transforms.ToTensor(),
# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
# ])
# )
# dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
Google Drive의 압축파일을 가상환경 Local로 복사
# Google Drive의 압축파일을 가상환경 Local로 복사
import shutil
src_path = "/content/drive/MyDrive/pytorch/img_align_celeba.zip"
shutil.copy(src_path, dataroot)
# shutil: copy()-파일복사, copytree()-디렉토리 복사, move(): 파일/디렉토리 이동.
압축풀기
from zipfile import ZipFile
with ZipFile(os.path.join(dataroot, "img_align_celeba.zip")) as zfile:
zfile.extractall(dataroot)
Dataset, Dataloader
# Dataset, DataLoader 생성
transform = transforms.Compose([
transforms.Resize(image_size), # Resize((h,w)), Resize(정수): h/w중 짧은쪽의 크기를 지정. 긴쪽은 원본 이미지 종횡비에 맞춰 resize
transforms.CenterCrop(image_size), # CenterCrop(정수): 정수 X 정수 로 Crop
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # -1.0 ~ 1.0
dataset = datasets.ImageFolder(root='datasets/celaba', transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
생성 확인
print('데이터 총개수:', len(dataset))
print('에폭별 step수:', len(dataloader))
다운받은 일부 이미지 확인
vutils.make_grid: https://pytorch.org/vision/main/generated/torchvision.utils.make_grid.html
- 여러 이미지 Tensor 를 하나로 합친 Tensor를 반환한다.
< vutils.make_grid() 의 Parameter >
- tensor (Tensor or list): 4D mini-batch Tensor (Batch, Channel, Height, Width) 또는 같은 크기의 이미지 리스트
- nrow (int, optional): 한 행에 표시될 이미지의 개수. 최종 그리드의 형태는 ( Batch / nrow, nrow )가 된다. (Default : 8)
- padding (int, optional): 이미지 사이 간격 pdding (Default : 2)
- normalize (bool, optional): True 일 경우, image 를 0~1 값으로 변환. (value_range 파라미터의 min, max 값을 기준) (Default : False)
- pad_value (float, optional): 패딩 되는 픽셀의 값 (Default : 0)
첫번째 배치 확인
real_batch = next(iter(dataloader)) # 첫번째 배치
64개 이미지 grid로 확인
plt.figure(figsize=(10, 10))
plt.axis("off")
plt.title("Training Images")
plt.imshow(vutils.make_grid(real_batch[0][:64] # 0:X, [:64]: 128장 중 앞 64장
, padding=2 # 이미지사이 간격
, normalize=True, nrow =8).permute(1, 2, 0))
plt.show()


모델 정의
GAN 모델은 Generator와 Discriminator 두 개 모델을 정의한다.
모델을 구성하는 Layer 의 파라미터 초기화
▪️ DCGAN 논문에서 저자에서 모든 모델 가중치를 평균=0, 표준편차=0.02의 정규 분포에서 무작위로 초기화
▪️ `weights_init()` 함수는 Random값으로 초기화된 모델을 입력으로 받아 위 기준을 충족하도록 모든 convolution, convolution-transpose 및 Batch Normalization 레이어의 파라미터들을 다시 초기화한다.
논문에 따라 파라미터 초기화하는 함수
- nn.init.normal_(텐서, 평균, 표준편차): 텐서를 평균, 표준편차를 따르는 정규분포의 난수들로 채운다.
- nn.init.constant_(텐서, value): 텐서를 value:float 으로 채운다.

## 논문에 따라 레이어의 파라미터들을 초기화하는 함수.
# nn.init.normal_(텐서, 평균, 표준편차): 텐서를 평균, 표준편차를 따르는 정규분포의 난수들로 채운다.
# nn.init.constant_(텐서, value): 텐서를 value:float 으로 채운다.
def weights_init(m:"Layer"):
classname = m.__class__.__name__ #레이어객체의 클래스 이름
if classname.find('Conv') != -1: # Convolution Layer일 경우
nn.init.normal_(m.weight.data, 0.0, 0.02) # weight를 평균 0, 표준편차 1로 초기화
elif classname.find('BatchNorm') != -1: # Batchnormaliztion Layer일 경우
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)a = nn.Conv2d(10,10,3)
cn = a.__class__.__name__
cn
cn.find("Conv") #문자열A.find("문자열B") => 문자열A에 문자열B가 어디있는지 index를 반환
# cn.find("Batch")
# 찾음 :인덱스위치 : 0 - 처음부터 시작, 못찾음: -1
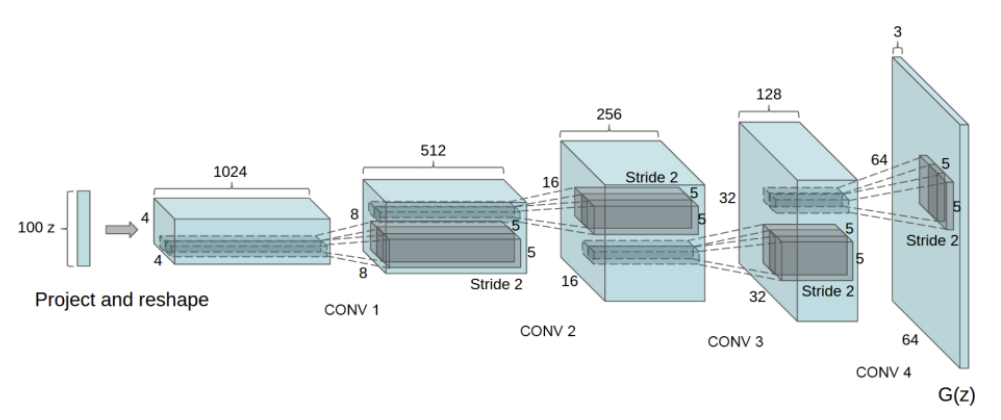
Generator(생성자) 모델 정의
▪️ Generator는 Latent space Vector(잠재공간벡터) 를 입력 받아 training image와 동일한 형태(분포)의 이미지를 생성
- Latent space Vector는 GAN의 입력데이터로 동일한 분포(보통 정규분포)의 random 값으로 구성된다.
- random 값이 어떻게 구성되느냐에 따라 다른 이미지가 생성된다.
▪️ Generator는 Strided Transpose Convolution, Batch Normalization, ReLU 로 이어지는 layer block들로 구성된다.
- Strided Convolution : pooling layer를 사용하지 않고 stride를 이용해 size를 조정하는 것을 말함.
- Transpose Convolution : Convolution을 역으로 계산한다. 보통 Upsampling에 사용된다.
- Generator의 최종 출력은 [-1, 1] 범위의 결과를 리턴한다. 그래서 출력 Layer의 activation 함수로 tanh를 사용한다.
Transpose Convolution layer 출력 size 공식
- 합성곱 연산의 역연산을 수행하는 레이어이므로, 업샘플링(upsampling) 작업을 위해 사용된다.
- i: input 크기 - 입력레이어의 크기
- k: kernel 크기(filter의 크기)
- s: stride - 필터의 이동 간격(출력 크기를 변화 시킴)
- p: padding
- output_size = (kernel 크기 + ( input 크기 -1) X stride - 2 X padding)
# input size = (64, 64)
# output size = (k_s + (i_s -1) * s - 2*p)
i_s = 64 # input size
k_s = 4 # kernel(filter) 크기
s = 2 # stride
p = 1 # padding
(4 + (64-1) * 1 - 2 * 0)
((k_s + (i_s -1) * s - 2*p), (k_s + (i_s -1) * s - 2*p))
transpose convolution layer 이해
Transpose Convolution은 Convolution 레이어와 마찬가지로 필터 값을 학습해서 Upsampling을 수행합니다.

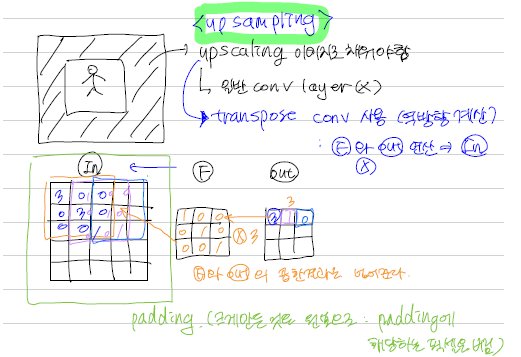
layer = nn.ConvTranspose2d(in_channels=1, out_channels=3, kernel_size=4, stride=2, padding=1)
i_data = torch.ones((1, 1, 64, 64))
result = layer(i_data)
print(result.shape)
Generator
: Strided Transpose Convolution + Batch Normalization + ReLU

class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input: (100, 1, 1) -> (64 * 8, 4, 4)
nn.ConvTranspose2d(in_channels=nz,
out_channels=ngf * 8,
kernel_size=4,
stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
Generator를 생성하고 `weights_init` 함수를 적용
: `weights_init()` 함수는 Random값으로 초기화된 모델을 입력으로 받아 위 기준을 충족하도록 모든 convolution, convolution-transpose 및 Batch Normalization 레이어의 파라미터들을 다시 초기화
# Generator 생성
netG = Generator(ngpu).to(device)
netG.apply(weights_init)
print(netG)
Discriminator(판별자) 모델 정의
▪️ Discriminator는 trainset의 진짜 이미지와 generator가 생성한 가짜 이미지를 분류
- 이미지를 입력받아 이진분류를 해서 진짜이미지 인지 여부의 확률값을 출력한다.
- 모델의 구조는 Strided Convolution layer, Batch normalization, LeakyReLU 로 구성된 layer block들을 통과한 뒤 sigmoid activation 함수를 통해 최종 확률값을 출력
▪️논문과의 비교
- 논문에서 Activation 함수로 ReLU가 아닌 LeakyReLU를 사용한 것이 특징
- 논문에서는 down sampling을 max pooling 이 아니라 convolution layer의 stride를 이용해 줄여 나감
( 이유는 pooling layer를 사용할 경우 convolution layer가 pooling 함수를 학습하게 되기 때문 )

Discirminator(판별자 모델 정의)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)Discriminator 생성
# Discriminator 생성
netD = Discriminator(ngpu).to(device)
netD.apply(weights_init)
print(netD)
Train
1. loss함수와 Optimizer 설정
- GAN 모델의 최종 출력은 Real image인지 여부이므로 이진분류 문제이다.
- Loss 함수는 Binary Cross Entropy loss (BCELoss) 함수를 사용.
import torch
torch.optim.Adam?criterion = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.
fake_label = 0.
optimizerD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
2. Training
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
s_all = time.time()
for epoch in range(num_epochs):
s = time.time()
for i, data in enumerate(dataloader, 0):
####################################################################################
# (1) Update Discriminator(판별자) network Traing
###################################################################################
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
output = netD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
# 판별자의 fake 이미지를 넣어서 분류(추정)한다.
output = netD(fake.detach()).view(-1)
# loss
errD_fake = criterion(output, label)
# gradient 계산
errD_fake.backward()
D_G_z1 = output.mean().item() # 맞은 것(생성자)의 비율
# 생성자 파라미터 업
errD = errD_real + errD_fake
optimizerD.step()
#######################################################
# (2) Update Generator(생성자) network Traning
#######################################################
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
if i % 50 == 0: # 50 step에 한번씩 로그를 출력
print('[{:02d}/{}][{:04d}:/{}]\tLoss_D: {:.4f}\tLoss_G: {:.4f}\tD(x): {:.4f}\tD(G(z)): {:.4f} / {:.4f}'.format(
epoch+1, # 현재 몇 번째 epoch인지
num_epochs, # 총 epoch
i, # 현재 epoch에서 몇 번째 step인지.
len(dataloader), # 총 step 수
errD.item(), # 판별자 loss
errG.item(), # 생성자 loss
D_x, # 판별자가 real image에 대해 맞은 비율
D_G_z1, # 판별자가 fake image에 대해 틀린 비율
D_G_z2 # 생성자가 판별자를 잘 속인 비율
))
G_losses.append(errG.item())
D_losses.append(errD.item())
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
e = time.time()
print(f"{epoch+1} epoch 걸린시간: {e-s}초")
e_all = time.time()
print(f"총 걸린 시간: {e_all - s_all}초")
학습결과 시각화
- G_losses, D_losses 비교
### 학습결과 시각화
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="Generator")
plt.plot(D_losses,label="Discriminator")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
이미지 출력
- show_fake_image(n)
def show_fake_image(idx):
"""학습도중 저장한 fake 이미지를 출력"""
plt.figure(figsize=(10,10))
img = img_list[idx].permute(1,2,0)
plt.imshow(img)
plt.show()
show_fake_image(32)
Train set의 이미지와 생성한 이미지 비교
# Tain set의 이미지와 생성한 이미지 비교
# real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(20,20))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(vutils.make_grid(real_batch[0][:64], padding=5, normalize=True).permute(1,2,0))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| Object Detection | 개요 + 성능평가 (0) | 2023.11.07 |
|---|---|
| 데이터 수집과 라벨링 | Open Dataset + 데이터 수집 방법 (0) | 2023.11.06 |
| GAN 개념 | 진짜와 구별이 안되는 Generator 모델 (0) | 2023.11.04 |
| LSTM 주가예측 | 삼성전자의 주가(시계열데이터)를 예측해보자 (0) | 2023.11.04 |
| RNN 개요 | RNN (1) | 2023.11.01 |


