https://dacon.io/competitions/open/235698/overview/description
[DACON_101] Lv.1 의사결정회귀나무로 따릉이 데이터 예측하기를 공부하고 정리한 내용
우선, 데이터 다운로드 링크로 데이터를 코랩에 불러온다.
!wget 'https://bit.ly/3gLj0Q6'
import zipfile
with zipfile.ZipFile('3gLj0Q6', 'r') as existing_zip:
existing_zip.extractall('data')모델을 학습시키는 과정은 EDA, 전처리, 모델링의 3단계를 거친다.
1단계 : EDA(Exploratory Data Analysis)
1. 라이브러리, 파일 불러오기
pandas라이브러리를 불러오고, data폴더에 있는 test.csv , train.csv 파일을 불러오기
1) 라이브러리 불러오기
import pandas as pd
2) 데이터 불러오기
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
2. 행 열 갯수 관찰
shape를 이용해 행/열의 갯수를 확인한다.
train.shape
test.shape
3. 데이터 확인하기 (head())
head를 이용해 데이터의 상단부분 확인
train.head()
test.head()
4. 결측치 확인하기 isnull() / isnull.sum() 열별 결측치 확인
isnull() 메서드를 사용해 train과 test의 NAN를 확인
print("train 데이터 프레임의 결측치 여부 확인")
print(train.isnull())
print("train 데이터의 열별 결측치 수 확인")
print(train.isnull().sum())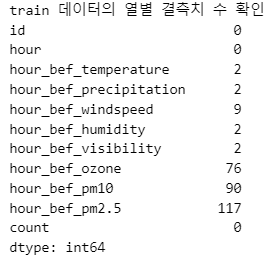
2단계 : 전처리
전처리 단계에서 사용할 함수는df.info()dropna()fillna(대체값)
3가지 이다.
(1) 전처리를 위해서는 df.info()로 데이터의 기본정보(결측치와 데이터 타입 등)를 확인한다.
train.info()
test.info()info를 통해 결측치를 확인했다면, 모델링에 앞서 결측치를 어떻게 다룰지 고민하고 처리하는 과정이 필요하다
train data
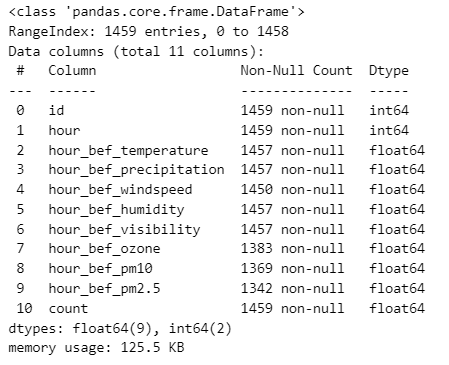
train 데이터를 확인하니, 전체 1459행을 가지는 데이터에서 ,hour_bef_temperature, hour_bef_precipitation, hour_bef_windspeed, hour_bef_humidity, hour_bef_visibility, hour_bef_ozone, hour_bef_pm10, hour_bef_pm2.5(index 2~9) 총 8개 column에서 결측치가 발견되었다.
test data
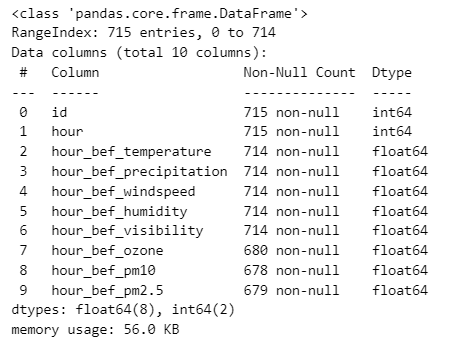
train 데이터를 확인하니, 전체 715개 데이터에서 train데이터와 동일한 8개의 컬럼에서 결측치가 발견되었다. test 데이터에는 count컬럼(결과값)이 존재하지 않으므로 이는 제외한다.
(2) 결측치를 확인했다면, 결측치를 갖는 행을 dropna()를 이용해 df에서 삭제하거나, fillna(대체값)으로 결측치를 인자값으로 대체한다.
- train의 결측치는 모두 제거하고, test의 결측치는 모두 0으로 대체
train = train.dropna()
test = test.fillna(0)
결측치가 잘 처리되었는지 확인하기 위해 열별 결측치 수를 체크
print(train.isnull().sum())
print(test.isnull().sum())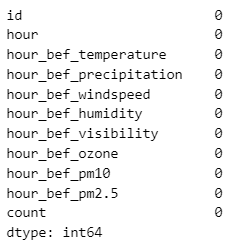
잘 제거되었음을 확인할 수 있다.
3단계 : 모델링
※ 의사결정나무란?
- 결정 트리는 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종입니다. 즉, 스무고개 방식으로 구조화되는 것입니다.
- 하나의 피쳐를 정해 해당 피쳐의 특정한 하나의 값을 정해서 이를 기준으로 모든 행을 두개의 노드(node)로 분류(이진분할, Binary decision rule)할 수 있음
- 결론에 도달할 때까지 연속적인 '예/아니오' 질문들을 반복해 최종 의사결정을 하는 방법
- 의사결정나무의 대원칙은 '한쪽 방향으로 쏠리도록하는 것' -> 공평하게 나뉘도록 정하는 것이 아니라 한쪽 방향으로 쏠리도록 하는 특정한 값을 '불순도계산'으로 찾아냄
- scikit-learn 에서 모듈을 불러옴
import sklearn from sklearn.tree import DecisionTreeClassifier - 예 : CART 의사결정 나무(이진분할)
1. 모델 라이브러리 불러오기
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
2. 모델 생성/선언
의사결정나무는 DecisionTreeClassifier -분류모델(예측값으로 0/1이산값 출력) , DecisionTreeRegressor - 회귀모델(예측밧으로 연속값 출력)로 나뉜다.
여기서는 회귀모델을 사용한다.
model = DecisionTreeRegressor()
3. 모델 훈련
모델을 선언한 후 `fit(X,Y)`함수를 사용해 모델을 훈련시키
X 데이터는 예측에 사용되는 변수, y 데이터는 예측결과와 관련된 변수를 의미한다.
X_train = train.drop(['count'], axis = 1)
y_train = train['count']
model.fit(X_train, y_train)
4. test 데이터 예측
predict() 매서드에 예측하고자하는 data를 인자로 넣어주면 결과 array를 할당할 수 있음
pred = model.predict(test)
pred[:5] # 상위 5개 결과 예측
5. 제출파일 생성
submission = pd.read_csv('data/submission.csv')
submission['count'] = pred
submission.to_csv('sub.csv', index = False)'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| [Module 4] 6.Ensemble | 머신러닝 모델을 동시에 사용하기 (1) | 2024.01.10 |
|---|---|
| Lv2. 결측치 보간법과 랜덤포레스트로 따릉이 데이터 예측하기 (1) | 2023.12.26 |
| Segemntation | 개요 (1) | 2023.11.09 |
| Object Detection | yolov8 예제 2(customdataset_train.) (0) | 2023.11.09 |
| Object Detection | yolov8 예제1(저장된 datasets) (0) | 2023.11.07 |


