YOLO (You Only Look Once)
2015년 발표된 Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi이 발표한 Object Detection 모델.
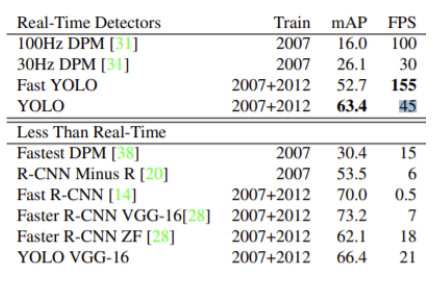
mAP(성능) - 최신 모델이 50~70대로(DPM은 기존모델) 성능이 훨씬 좋아진 것을 볼 수 있음.
FPS(1초당 인식가능 이미지수) - 기존 모델은 실시간인식이가능하지만 최신모델은 인식속도가 빠르지 않아 실시간 인식 불가
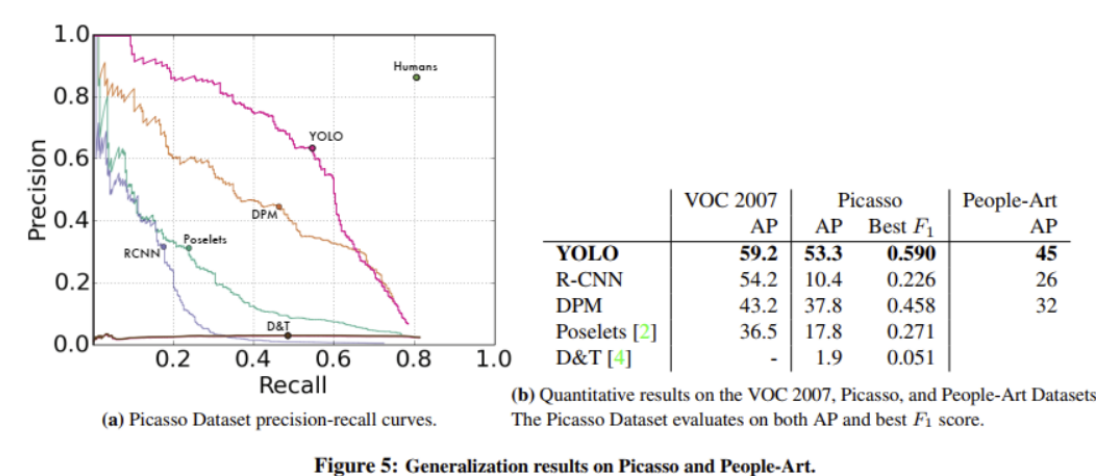

단점
- 기존의 2stage detection에 비해 낮은 성능
- 작은 물체에 대한 감지력떨어짐(공통적인 단점)
youtube강연
YOlO prediciton(추론단계)
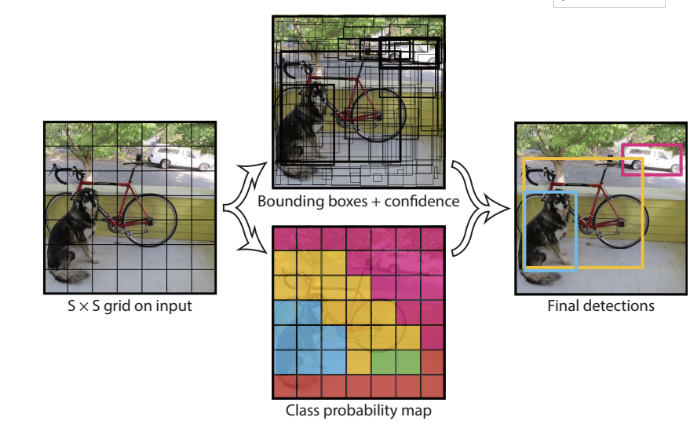
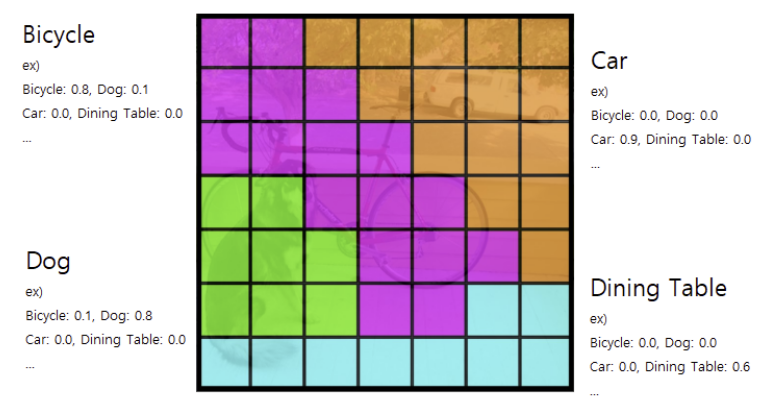
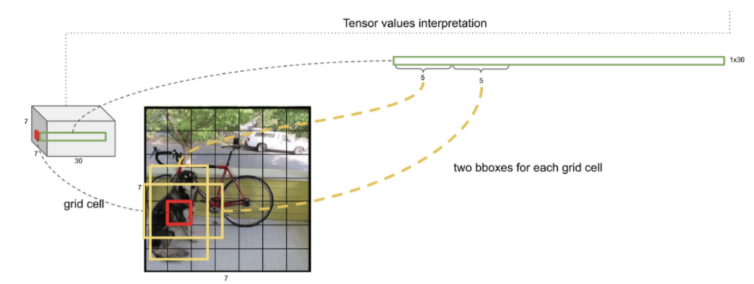
1단계 : 전체 이미지를 S X S 의 grid로 나눈다. (S: 7)

2단계 : 각 Cell에서 Bounding Box와 Confidence 예측

- 각 cell에서 B(2)개의 Bounding Box와 그 Bounidng Box에 대한 신뢰점수(Confidence)를 예측한다.
- Bounding Box는 (c, x, y, w, h) 5개의 값으로 구성된다.
- (x,y)는 중심점의 좌표, (w,h)는 bounding box의 너비의 높이, c는 해당 bounding box에 대한 신뢰점수(Confidence)
- Confidence: 물체가 있을 확률 * IoU점수(Ground truth와 예측bbox간의 겹치는 부분의 넓이)
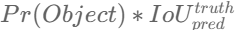
3 단계 : 각 cell에서 C개의 class별 확률을 예측한다.
(C: 검출할 class 개수 - Pascal VOC: 20개)
- Class일 확률:
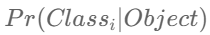
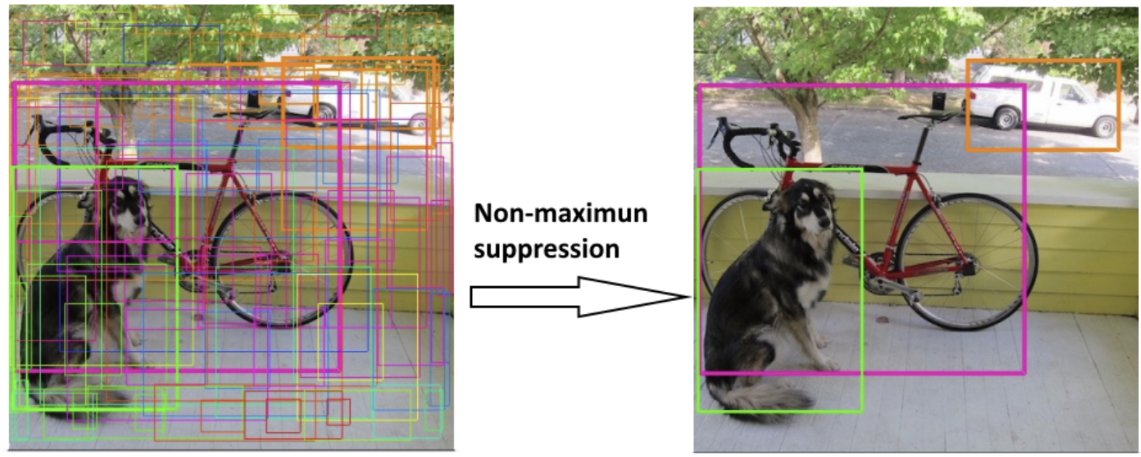
YOlO prediciton 최종 출력(예측) 결과
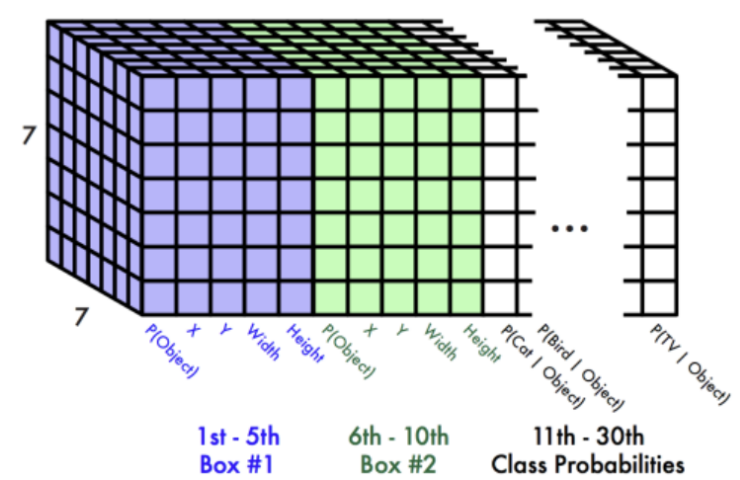
- (7, 7, 30) shape 으로 반환
Yolo model은
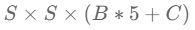
shape의 3차원 Tensor로 출력한다.
- S: grid 개수 - (논문 - 7)
- B: Grid별로 예측할 Bounding Box의 개수 (논문 - 2) - 5ro
- C: class개수 (논문에서는 Pascal VOC 데이터셋을 사용. Pascal VOC class개수 - 20개)
- 논문의 최종 결과는 (7,7,(2*5+20)=>(7, 7, 30) shape으로 반환됨
=> (7, 7, 30) shape은 7x7 grid cell에 대해 box 1(c,x,y,w,h) 5개 + box 2(c,x,y,w,h) 5개 + 파스칼 classes 20개 = 30개로 나열된형대이다.(박스가 2개인 경우)
출력결과의 네트워크 구조 - convolution layer
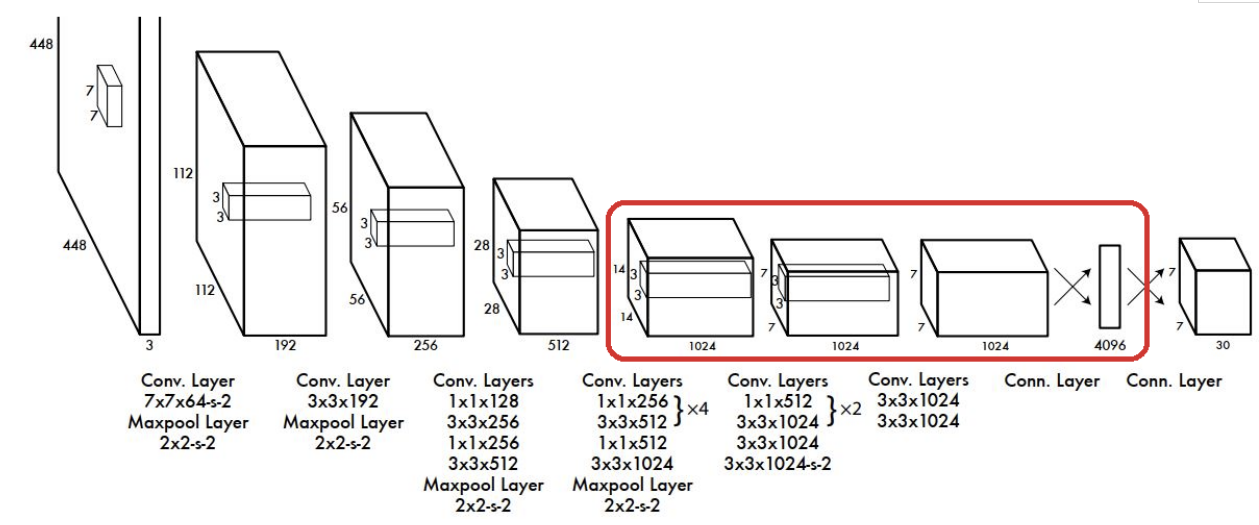
- 네트워크 구조는 단순한 Convolution Network 이다.
- 입력으로 448 X 448 이미지를 받는다.
- 학습시 Bounding box 좌표(cx, cy, w,h) Ground Truth Label은 전체 이미지 width, height 기준의 비율로 0~1사이 실수로 normalize한다.
- Activation Function으로 Leaky ReLU를 사용하였고 마지막 출력 Layer만 Linear Function을 사용함. - Fully Connected Layer를 통과하여 나온 결과를 ($7 \times 7 \times 30$) 형태로 reshape해서 최종 결과로 출력한다.
- 앞단의 20개의 Layer들은 Base Network(Backbone-특징 추출 네트워크))으로 $224 \times 224$ 크기 이미지넷 데이터셋으로 Pretrain의 시켰다.
- 학습시 Base Network(Backbone) 레이어들은 Frozen(고정) 시키고 위 그림의 붉은 Box의 Convolution Layer들을 Object Detection Task에 맞춰 Transfer Learning을 함.
Loss Fuction
:
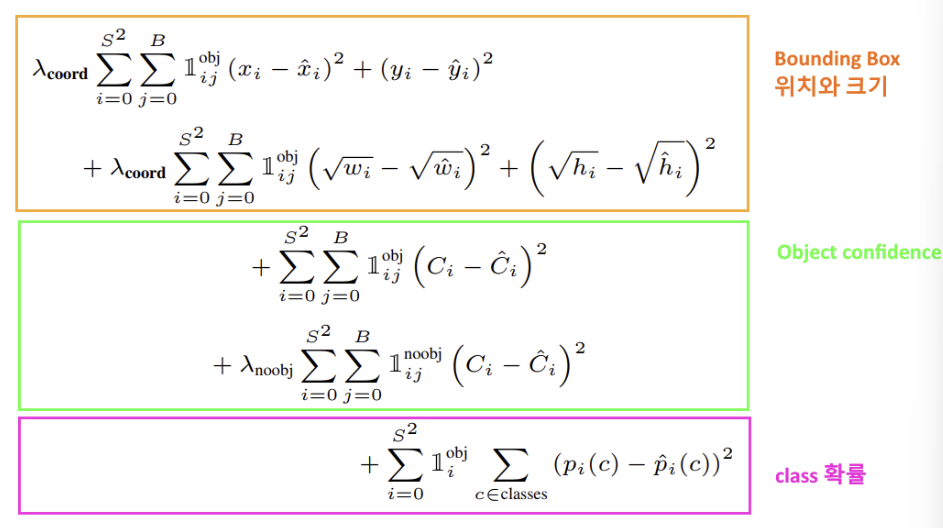

'■ Data Science Lab > ML & DL' 카테고리의 다른 글
| Object Detection | yolov8 예제 2(customdataset_train.) (0) | 2023.11.09 |
|---|---|
| Object Detection | yolov8 예제1(저장된 datasets) (0) | 2023.11.07 |
| Object Detection | 개요 + 성능평가 (0) | 2023.11.07 |
| 데이터 수집과 라벨링 | Open Dataset + 데이터 수집 방법 (0) | 2023.11.06 |
| GAN 실습 | DGan (1) | 2023.11.04 |


