1. Topic
ARAGOG: Advanced RAG Output Grading(2024) [LINK]
단순한 RAG(Naive RAG) 성능의 한계를 극복하기 위해 다양한 'Advanced RAG' 기법들이 연구됨.
그러나 너무나 많은 Advanced RAG 테크닉 중에 어떤 것이 효과적인지 파악하기 어려움
ARAGOG: Advanced RAG Output Grading에서는 주요 Advanced RAG 기법들의 성능을 비교하여,
RAG 기법 선택에 유용한 정보를 제공.
다양한 테크닉을 검색 정밀도와 답변 유사성으로 평가한 결과를 공개
연구 배경
논문에서 다룬 문제와 배경을 간단히 소개 (1~2분)
✔️ RAG 소개
RAG란?
Indexing → Retrieval → Generation 단계를 통해 외부 지식을 참조하여 LLM이 답변을 생성하는 방법
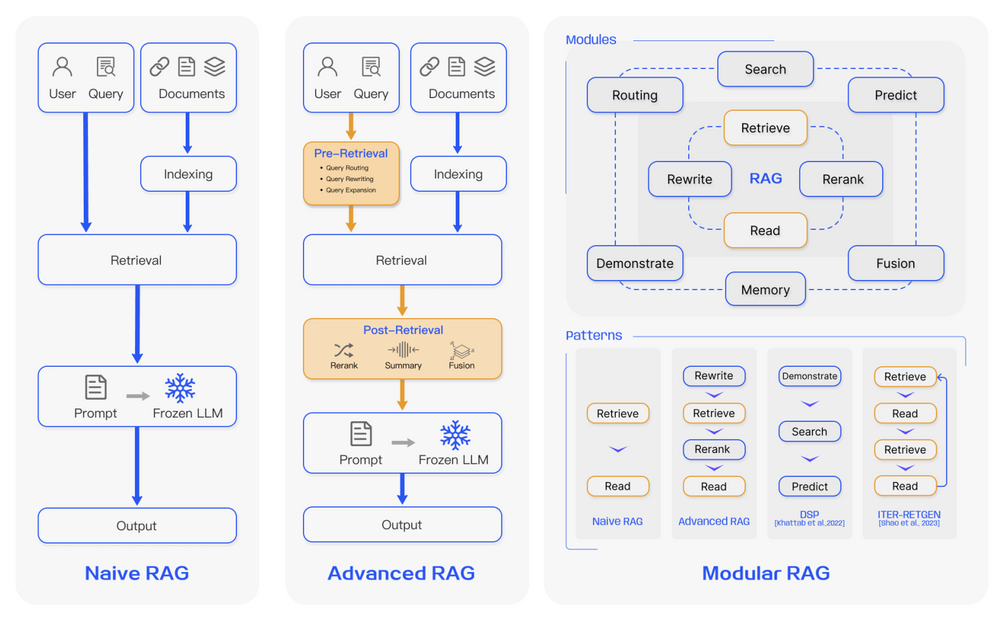
RAG 최신동향

Naive RAG
- 가장 초기 RAG, 전통적인 방식
- 단점 ❗ :
- Retrieval Challenges
- Retrieval phase에서 정확도(precision) 및 재현율(recall)이 좋지 않아 중요 정보를 빠뜨리는 경우가 있다.
- Generation Difficulties: 여전히 hallucination 이슈가 생길 수 있다.
- Augmentation Hurdles
- : 다른 종류의 task에서 가져온 Retrieved 정보를 합치는 것이 어려워 LLM에게 좋은 context를 전달하기 힘들다.
- 예를 들어 문맥이 일치하지 않거나 아예 일관성이 없는 정보가 나올 수도 있고, 중복이 나올 수 있다. 또한 어떤 정보가 중요한지 선택하거나 서로 연관성이 있는 지, 문체나 톤의 일관성을 보장하는 작업 등 복잡한 작업들이 필요하다.
Advanced RAG - Native RAG에서 Retrieval 질을 향상시키기 위해 pre-retrieval과 post-retrieval을 추가로 사용
- pre-retrieval → Indexing Structure 개선, Query 최적화 등
- post-retrieval → 검색한 context + 입력 Query와 효율적으로 합치는 방법 개선
- rerank chunk, context compressing
- Reranking에는 LlamaIndex, LangChain, HayStack 등을 사용
Modular RAG*- 가장 최신 경향
- NaiveRAG, AdvanedRAG의 패러다임 넘어 발전된 adaptability을 제공
- 예 ) similarity search를 위한 검색 모듈을 추가, fine-tuning을 통해 Retriver정제 등 “모듈” or “패턴”형태로 작업 제공
- (Retrieval-Augmented Generation for Large Language Models: A Survey)
- RAG는 3가지 카테고리로 나누어짐
- RAG에서 가장 중요한것 : RetrievalRAG에서 통제할 수 있는 것은 Retrieval로 가져오는 문서2) 가져온 문서들을 쿼리와 조합하여 LLM에 어떻게 넘길 것인가
- 1) 어떻게 문서를 잘 가져올 것인가
- RAG는 비용이나 시간적인 문제로 LLM을 Fine tuning하기 어려울 때 선택
ARAGOG: Advanced RAG Output Grading(2024)
- RAG(검색 증강 생성)는 외부 지식을 LLM 출력에 반영하기 위해 많이 사용됨
- RAG의 활용과 연구가 늘고 있지만, 다양한 RAG 테크닉에 대한 실험 비교 연구는 없음
- 본 논문은 주요
Advanced RAG 테크닉을 검색 정확도와 답변 유사성으로 평가한 결과를 공개

주요 연구 방법
연구가 어떤 방법론을 사용했는지 설명
Advanced RAG 테크닉- 7가지 기법 : [SWR] [DSI] [HyDE] [MQ] [MMR] [CR] [LR]
- 1 [SWR]Sentence-window retrieval
- 검색 단계에서는 문서를 문장 단위로 분할하여 세밀한 검색을 수행(가장 적절한 1개의 문장을 선택)
- ⇒ 생성 단계에서는 검색된 문장 주변의 문맥을 함께 제공하여 LLM이 더 풍부한 답변을 생성하도록 지원
- 검색된 문장 주위의 문장들도 추가함으로써 LLM이 답변 생성시 더 풍부한 컨텍스트 정보 활용이 가능
-

- LlamaIndex Code
window: 그럼에도 불구하고, 대부분 위치와 계절에서예상되는 미래 연간 누적 상승류 바람 변화는현재 값의 ±10~20% 범위 내에 있습니다(중간 신뢰도)(WGI AR6 섹션 9.2.3.5; Fox-Kemper et al., 2021).대서양 경도 순환(AMOC)에 대한 지속적인 관찰은 그 변동성에 대한 이해를 개선했지만(Frajka-Williams et al., 2019), 정량적 재구성 및 시뮬레이션 추세에 대한 일치도가 낮아 20세기 AMOC 변화의 정량화 에 대한 신뢰도가 낮습니다 (WGIAR6 섹션 2.3.3, 9.2.3.1; Fox-Kemper et al., 2021; Gulev et al., 2021). 2000년대 중반 이후의 직접적인 관측 기록은 내부 변동성, 자연적 강제력 및 인위적 강제력이 AMOC 변화에 미치는 상대적 기여도를 판단 하기에는 너무 짧습니다(높은 신뢰도) (WGI AR6 섹션 2.3.3, 9.2.3.1; Fox-Kemper 등, 2021; Gulev 등, 2021). 21세기에 AMOC는 모든 SSP 시나리오에서 감소할 가능성이 매우 높지만 2100년 이전에는 갑작스러운 붕괴는 수반되지 않을 것입니다(WGI AR6 섹션 4.3.2, 9.2.3.1; Fox-Kemper 등, 2021; Lee 등, 2021). 3.2.2.4 해빙 변화 해빙은 극지 해양 생물의 주요 원동력으로, 독특한 생태계를 보유하고 있으며 빛의 침투와 영양소 및 유기물 공급에 미치는 영향을 통해 다양한 해양 유기체와 먹이 사슬에 영향을 미칩니다 (Arrigo, 2014). 1970년대 후반부터 북극 해빙 면적은 모든 달에 걸쳐 감소해 왔으며, 2010~2019년의 여름 해빙(8월, 9월, 10월 평균)은 1979~1988년에 비해 200만 km2(또는 25%)가 감소한 것으로 추산됩니다(WGI AR6 섹션 9.3.1.1; Fox-Kemper 등, 2021). from llama_index.core.postprocessor import MetadataReplacementPostProcessor query_engine = sentence_index.as_query_engine( similarity_top_k=2, # the target key defaults to `window` to match the node_parser's default node_postprocessors=[ MetadataReplacementPostProcessor(target_metadata_key="window") ], ) window_response = query_engine.query( "What are the concerns surrounding the AMOC?" ) print(window_response)
원문: 21세기에 AMOC는 모든 SSP시나리오에서 매우 감소할 가능성이 높지만 2100년 이전에는 갑작스러운 붕괴는 일어나지 않을 것입니다(WGIAR6 섹션 4.3.2, 9.2.3.1; Fox-Kemper 등, 2021; Lee 등, 2021). - 2 [DSI]Document summary index
문서의 요약과 청크들을 색인화 =>DB에 저장- 사용자가 질문하면 요약된 정보로 빠르게 검색하고, 필요하면 전체 문서를 기반으로 상세한 답변을 제공[1단계] 샘플 문서[2단계] 생성된 요약본 저장(색인화)
doc1.txt내용:Climate change에 대한 긴 내용doc2.txt내용:Artificial intelligence (AI)에 대한 긴 내용-

doc1요약: "Climate change and its global impacts."doc2요약: "Applications of AI in various industries."- [3단계] 사용자 질문과 응답
- 질문:* "What is the main topic of the documents?"The documents cover topics related to climate change and its global impacts, as well as the applications of AI in various industries.
- → 응답(사용자 질문에 따른 색인된 요약본 검색 → 필요시 전체 문서를 참조해 더 상세 답변 생성)
- 3 [HyDE] Hypothetical Document Embedding
- LLM을 활용하여 쿼리에 대한 가상 답변을 생성. 생성한 가상 답변을 쿼리로 사용하여 관련 청크 검색
- 쿼리와 청크의 표현 차이로 인한 임베딩 검색 성능 저하를 개선
- 사용자의 구체적이지 않은 질문을 → LLM을 통해 구체화 시켜 문서와의 유사도 향상
- 검색 성능 향상 : 쿼리-문서간 표현 차이 감소 시킴
- 예)
- 👩🍳
- 쿼리*: "How does AI help in healthcare?"
- 청크*: "Artificial Intelligence is transforming the healthcare sector by enabling early disease detection, personalized treatments, and efficient hospital management."
⇒ 같은 주제, 다른 표현 방식과 단어 → 벡터 거리가 멀어져 관련 문서를 찾기 어려워짐

1. 원문 문서 → 2. 가상의 답변 생성(LLM 사용자 질문에 대한 가상의 답변을 생성 후, 문서 검색의 쿼리로 사용 ) → 3. 문서와 유사도를 계산(DB의 저장된 문서와 유사도를 계산하여 검색) → 4. 결과 출력
```python
# 2. LLM 초기화
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
# 3. HyDE: 가상의 답변 생성
query = "What are the effects of climate change on ecosystems?"
generated_answer = llm.complete(prompt=f"Answer this question based on your knowledge: {query}")
print(f"Generated Hypothetical Answer: {generated_answer}")
>>> 가상 답변 : Climate change affects ecosystems by causing habitat loss, species extinction, and changes in biodiversity due to rising temperatures and altered weather patterns.
# 4. 가상 답변을 사용해 문서 검색
# 문서와 가상 답변 간의 유사성을 계산하여 검색 수행
index = GPTListIndex.from_documents(documents)
response = index.query(generated_answer)
# 5. 검색 결과 출력
print("Relevant Documents:")
print(response)
>>> 가장 관련성 높은 문서 :
Climate change is causing significant disruptions to ecosystems. Rising temperatures lead to habitat loss, species migration, and biodiversity decline.
```
- **4 [MQ] Multi-query**
- LLM을 활용하여 쿼리와 유사한 여러개의 유사 쿼리 생성 → 다양한 관점에서 관련 문서를 검색하는 기법
- 원본 쿼리 + 유사 쿼리를 바탕으로 청크 검색
- 필요시 원본 쿼리와 가장 관련이 높은 청크에 우선순위를 부여하는 Rerank 기법 적용

단일 쿼리의 한계 : 사용자의 입력쿼리가 간결하거나 불완전 → 구체적인 내용이 포함되지 않아 벡터 검색의 효율성 떨어짐.
- 질문이 모호하거나 여러 해석이 가능한 경우, Multi-Query는 특히 유용.
- 예: "AI의 이점"이라는 질문은 의료, 교육, 금융 등 여러 맥락에서 다르게 해석될 수 있음.
예) **Multi-Query**
- 원본 쿼리: "How does AI help in education?"
- 파생 쿼리:
- "What are the benefits of AI in learning environments?"
- "How is artificial intelligence used in teaching?"
- "AI applications in education systems."
- **5 [MMR] Maximum Marginal Relevance**
1)`검색되는 청크의 중복성을 피하고` 2) 쿼리와 관련성 있는 `다양한 청크를 LLM`에 제공함
- 청크들간의 **유사성**과 **다양성**을 측정하는 **MMR 점수 계산**을 통해 중복되지 않는 다양한 청크를 선택
- 처음에는 쿼리와 가장 관련성 높은 문서를 선택.
- 이후에는 **관련성이 높으면서도 기존 문서들과 중복되지 않는 문서**를 반복적으로 선택.
- 수식 설명
- Di: 현재 평가 중인 문서.
- QQQ: 쿼리(Query).
- SSS: 이미 선택된 문서들의 집합.
- Sim(Di,Q)\text{Sim}(D_i, Q)Sim(Di,Q): 문서 Di와 쿼리 Q의 유사도.
DiD_i
QQ
- Sim(Di,Dj)\text{Sim}(D_i, D_j)Sim(Di,Dj): 문서 Di와 이미 선택된 문서 Dj 간의 유사도.
DiD_i
DjD_j
- λ\lambdaλ: 관련성과 다양성 간의 가중치 (0~1).
$$
MMR(Di)=λ⋅Sim(Di,Q)−(1−λ)⋅Dj∈SmaxSim(Di,Dj)
$$

+예)
- **쿼리**: "What are the latest AI trends?"
- **문서**:
1. "AI in healthcare: improving diagnostics."
2. "AI in transportation: self-driving cars."
3. "AI in healthcare: enhancing patient outcomes."
4. "Latest trends in AI for autonomous vehicles."
- 출력:
1. 처음에는 쿼리와 가장 관련 있는 문서 선택: "AI in healthcare: improving diagnostics."
2. 이후에는 중복을 피하기 위해 "AI in transportation: self-driving cars." 선택.
3. 세 번째로는 "Latest trends in AI for autonomous vehicles." 선택.
- **6 [CR]Cohere Rerank**
- 검색된 문서들의 순위를 재조정하여 쿼리와의 관련성이 높은 문서를 상위에 배치하는 기법
- 이를 통해 LLM이 더 정확한 정보를 우선적으로 활용

- **3.7 [LR]LLM rerank**
- 검색된 청크의 우선순위 재정렬 작업에 LLM을 직접 적용
- 크로스 인코더 모델에 비해 처리 속도와 비용 효율은 떨어지나, 더 높은 정확도를 달성할 수 있음- 2. 평가
- 인공지능과 LLM을 주제로 한 423개의 논문 선정
- 그중 13개의 논문에 대한 107개의 질문-답변 쌍 생성
- 질문-답변은 GPT-4를 사용하여 생성 후 사람이 검증
- 전체 423개 논문을 데이터 베이스로 하여 107개 질문에 대한 RAG 성능 평가
-

- 2.2 평가지표*
- Retrieval Precision와 Answer Similarity로 RAG 테크닉들을 비교 평가(GPT-3.5 사용)2) Answer Similarity : 생성된 답변이 실제 답변과 얼마나 잘 일치하는지를 0-5점 척도로 평가
- 1) Retrieval Precision : 쿼리와 청크와의 관련성 정도. 0~1점 범위의 점수로 정량화
- 2.1 데이터셋
2.3 평가결과
2.3.1 **Retrieval Precision**
- Sentence window retrieval이 가장 효과적
- LLM Rerank, HyDE도 Naive RAG보다 우수
- MMR과 Cohere Rerank는 Naive RAG보다 약간 나음
- Multi Query는 Naive RAG보다 안좋음
- Document summary index는 기존 Vector DB보다 우수
- 최고의 조합은 Sentence window retrieval + LLM Rerank

2.3.2 **Answer Similarity**
- Cohere/LLM Rerank, MMR은 Naive RAG보다 약간 나음
- HyDE는 Naive RAG보다 약간 떨어짐
- Multi Query는 Naive RAG보다 안좋음
- Document summary index는 기존 Vector DB보다 안좋음
- Sentence window retrieval은 가장 안좋음
- 최고의 조합은 Classic VDB + HyDE + Cohere Rerank
- 3.결론[SWR] Best/Worst[HyDE] Better/Average[MMR] Better/Average[LR] Better/Better
- HyDE와 LLM Rerank는 Retrieval Precision와 Answer Similarity 모두 좋은편
- MMR과 Cohere Rerank는 Naive RAG 대비 눈에 띄는 성과를 내지 못함
- Multi query는 두 지표 모두 성능이 낮음
- Sentence window retrieval은 Retrieval Precision은 가장 우수하지만, Answer Similarity는 최악임
- Document summary index는 Retrieval Precision에서만 조금 좋음
- [CR] Better/Better
- [MQ] Worst/Worse
- [DSI] Better/Worse
- [Techniques] Retrieval Precision/Answer Similarity
해당 논문에 대한 개인적인 생각
해당 방법론이 타당해 보인다든지, 어떠한 문제가 생길 것 같다든지..(1분)
3. 참고자료
논문리뷰
https://aiforeveryone.tistory.com/48
https://www.linkedin.com/posts/agostino-calamia_rag-data-llm-activity-7227576849416036353-U913/



