객체 탐지 모델 YOLO You Only Look Once: Unified, Real-Time Object Detection 논문을 리뷰한 게시글 입니다
1. 소개
1.1 Two-Stage Detector vs One-Stage Detector

regional proposal과 classification이 순차적으로 이루어짐. classification과 localization문제를 순차적으로 해결
E.G, R-CNN계열 (R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN ...)

regional proposal와 classification이 동시에 이루어짐 즉, classification과 localization문제를 동시에 해결하는 방법
E.G, YOLO 계열, SSD 계열 (SSD, RetinaNet, RefineDet ...)
따라서 1-stage detector는 비교적 빠르지만 정확도가 낮고
2-stage detector는 비교적 느리지만 정확도가 높음
1.2 YOLO introduction
You Only Look Once: Unified, Real-Time Object Detection
1) You Only Look Once : 전체 이미지를 보는 횟수 : 1회
2) Unified : Classification & Localization 단계 단일화
3) Real-Time : 속도 개선 RCNN 6fps > YOLO 45fps > Fast YOLO 155fps
YOLO(You Only Look Once: Unified, Real-Time Object Detection)"는 실시간 객체 검출 분야에서 중요한 이정표 중 하나
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi에 의해 2016년에 발표
객체 검출을 단일 신경망이 이미지 전체를 한 번만 보고 객체의 종류와 위치를 예측하게 함으로써, 기존 방법보다 훨씬 빠른 속도로 처리할 수 있게 하는 방법론을 제안
YOLO의 접근 방식은 이전의 객체 검출 시스템과 크게 달라, 실시간 처리가 가능하면서도 높은 정확도를 달성
✅이전 모델들의 문제
R-CNN과 같은 최신 접근 방식은 지역 제안을 사용
- 이미지에서 잠재적 경계 상자를 먼저 생성한 다음 이러한 제안된 상자에 대해 분류기를 실행
- 분류 후 후처리를 사용하여 경계 상자를 구체화하고, 중복 감지를 제거하고, 장면의 다른 개체를 기반으로 한
박스를 다시 채점 => 복잡한 파이프라인: 느리고 최적화하기 어렵다는 문제 존재
: 개별 구성 요소를 개별적으로 훈련하기 때문
✅ 문제 해결
유니티는 오브젝트 감지를 이미지 픽셀에서 경계 상자 좌표와 클래스 확률로 바로 연결되는 단일 회귀 문제로 재구성
: 이미지를 한 번만(YOLO) 보고 어떤 물체가 있는지 예측가능
YOLO 모델의 Inference 단계 시각

✅주요 개념 및 특징
1. 통합된 프레임워크
YOLO는 객체의 검출과 분류를 단일 회귀 모델로 처리함
이것은 이미지를 여러 부분으로 나누고 각 부분에 대해 객체의 존재 여부, 클래스, 위치를 동시에 예측
2. 속도와 정확도
YOLO는 매우 빠른 속도로 작동하며, 이는 실시간 시스템이나 비디오 스트림 분석에 특히 유용
발표 당시, YOLO는 초당 45프레임(FPS)을 처리할 수 있었습음
3. 일반화 능력: YOLO는 다른 객체 검출 시스템에 비해 배경 오류를 더 적게 일으키는 경향이 있음
이는 YOLO가 전체 이미지를 보고 객체를 예측하기 때문에, 객체의 일반적인 맥락을 더 잘 이해할 수 있기 때문임
4. Unified Architecture
하나의 신경망으로 Classification&Localization 모두 예측
5. 한계점: YOLO는 작은 객체들이 그룹으로 모여 있을 때 그들을 개별적으로 구분하는 데 어려움이 있었음
또한, 객체의 위치를 예측할 때 다른 방법들에 비해 정확도가 떨어질 수 있음
2. Unified Detection 구조 및 작동 원리
YOLO는 객체 탐지의 분리된 컴포넌트를 단일 신경망으로 통합
또한 YOLO의 디자인은 end-to-end 학습과 높은 AP를 유지하며 동시에 실시간의 속도를 가능케함
본 시스템의 구성 소개
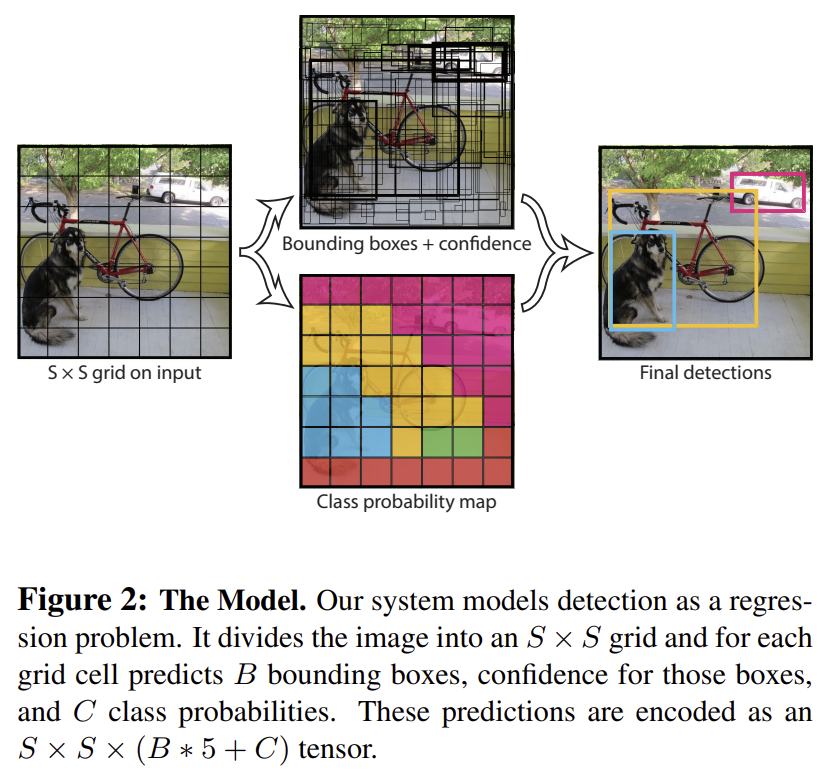
YOLO는 이미지를 SxS 그리드로 나누고, 각 그리드 셀이 객체의 중심을 포함할 경우, 그 객체를 검출함.
각 그리드 셀은 B개의 bounding box를 예측하고, 각 box는 box의 신뢰도 점수confidence score와클래스의 조건부 확률을 포함
-
- ✅ 바운딩 박스는 x,y,w,h와 신뢰, 5가지의 예측으로 구성
- (x,y)는 그리드 셀의 경계에 대해 상대적인 박스의 중심 좌표
- 너비와 높이는 전체 이미지에 대해 상대적인 좌표로 예측
- ✅신뢰도 점수Confidence score는 bounding box가 객체를 포함하고 있을 확률과 예측된 box가 정확한지를 나타내는 지표의 곱으로 계산
- 이 점수는 박스에 보여지는 클래스의 모습의 확률(클래스의 조건부 확률 C : Pr(Classi|Object))과 객체에 맞게 박스를 얼마나 잘 예측하고 있는지(예측된 신뢰도 IOUpredtruth)인코딩
- Pr(Object)∗IOUpredtruth

- ✅ 바운딩 박스는 x,y,w,h와 신뢰, 5가지의 예측으로 구성
최종적으로, 네트워크는 각 클래스에 대한 개별 객체의 확률을 출력 Pr(Classi∗IOUpredtruth)
이 확률은 confidence score와 결합되어 최종 점수를 형성하며, 이를 통해 객체의 위치와 클래스가 결정됨
시스템 구성
네트워크 디자인
네트워크의 초기 Convolution 층은 이미지의 피처를 추출하고 완전 연결층은 출력의 확률과 좌푯값을 예측한다. 네트워크 아키텍쳐는 GoogLeNet으로부터 영감을 받았으며 본 논문의 네트워크는 24개의 Convolution 층과 2개의 완전 연결층을 쌓았다. 또한 GoogLeNet에서 사용된 inception module 대신 3×3의 Convolution 층 뒤에 1×1의 축소 층을 사용했다. 전체 네트워크 디자인은 다음과 같다.

본 논문에선 YOLO의 빠른 버전인 Fast YOLO도 소개한다. 아키텍처는 기존 모델은 24개의 Convolution 층 대신 9개층을 사용하고 각 층의 필터도 기존 모델보다 적다. 네트워크 크기 외에 학습 및 테스트 파라미터는 기존 모델과 동일하다.
학습
Convolution 층은 ImageNet 1000-class 대회 데이터셋으로 약 1주일간 사전학습하였고 ImageNet 2012 검증 데이터셋에서 top-5 정확도는 GoogLeNet과 유사하게 88%였다. 학습과 추론시 Darnet 프레임워크를 이용하였다.
탐지는 종종 fine-grained 시각 정보를 요하기 때문에 네트워크 인풋 해상도를 224×224에서 448×448로 수정하였다. 마지막 레이어는 클래스 확률과 바운딩 박스 좌표를 예측한다. 바운딩 박스의 너비와 높이는 이미지의 너비와 높이로 정규화 되며 따라서 0과 1 사이의 값을 가지게 된다. 바운딩 박스의 x와 y 좌표값은 특정 그리드 셀의 오프셋으로 파라미터화 했으므로 이들 또한 0과 1 사이의 값을 가지게 된다.
마지막 층에는 선형 활성화 함수를 사용하였으며 다른 층은 leaky rectified linear activation을 사용하였다. leaky rectified linear activation은 다음과 같다.
ϕ(x)={x,ifx>00.1x,otherwise
손실 함수
sum-square error는 최적화(optimize)하기 쉽기 때문에 손실 함수로는 sum-squared error를 사용하였다.
sum-square error의 문제
1. 위치 에러와 분류 에러를 동일한 비중으로 다루기 때문에 average precision을 최대화 하고자 하는 논문에서의 목표와는 완벽하게 들어맞지는 않는다. 모든 이미지의 많은 그리드 셀은 객체를 포함하지 않기 때문에 그러한 셀들의 신뢰도 점수를 0으로 향하게 하며 종종 개체를 포함하는 셀의 기울기를 압도한다. (객체를 포함하지 않는 셀이 학습을 방해한다고 받아들였습니다.) 이는 모델이 불안정하기 해져 학습이 조기에 발산될 수 있다.
2. 큰 박스와 작은 박스의 에러를 동일한 비중으로 다룬다.
이에 대한 해결책
1번 문제를 해결하기 위해 바운딩 박스의 좌표 예측 손실을 증가시키고 객체를 포함하지 않는 박스의 신뢰도 예측 손실을 감소시킨다. 이를 λcoord와 λnoobj 두 파라미터로 이용하였고 논문에선 각각 5와 .5로 설정하였다.
2번 문제를 해결하기 위해 손실 함수가 큰 상자에서의 작은 편차가 작은 상자보다 덜 중요하다는 것을 반영하도록 해야한다. 따라서 본 논문에선 바운딩 박스의 너비와 높이의 값을 그대로 예측 하는 것이 아닌 루트값을 예측하도록 하였다.
YOLO는 그리드 셀당 여러 바운딩 박스를 예측한다. 학습시에는 각 객체별로 하나의 바운딩 박스만을 갖기를 바라기 때문에 예측값이 ground truth와 가장 높은 IOU 값을 가지지를 기반으로 하나의 객체를 담당하도록 한다. 이는 바운딩 박스 예측자 사이의 전문화(specialization)로 이어진다. 각 예측자는 특정 사이즈나 종횡비, 객체의 클래스에 대해 더 나아지고 전반적인 recall값도 개선된다.
이를 수식화하면 다음과 같다.
𝟙λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2]𝟙+λcoord∑i=0S2∑j=0B1ijobj[(wi−w^i)2+(hi−h^i)2]𝟙+∑i=0S2∑j=0B1ijobj(Ci−C^i)2𝟙+λnoobj∑i=0S2∑jB1ijnoobj(Ci−C^i)2𝟙+∑i=0S21ijobj∑c∈classes(pi(c)−p^i(c))2
여기서 𝟙1iobj 는 객체가 i번째 셀 속에 존재한다는 것을 의미한다.
𝟙1ijobj 는 i번째 셀 속 j번째 박스 예측자가 해당 예측을 담당한다는 것을 의미한다.
이는 손실 함수가 그리드 셀 속에 객체가 있을 때에만 classification error를 처벌(penalize)한다는 것을 의미한다. 또한 예측자가 ground truth 박스를 담당할 경우에만 바운딩 박스의 coordinate error를 처벌한다.
추론시엔 NMS(non-maximal suppression)을 적용하여 큰 객체나여러 셀 경계에 있는 객체가 잘 자리를 잡을 수 있도록 한다.
실험

다른 실시간 시스템들과 비교했을 때 현격히 빠르며 다른 실시간 시스템보다 훨씬 정확하다.

IOU가 .1 아래인 것을 배경이라 가정했을 때 배경 에러가 Fast R-CNN에 비해 YOLO가 훨씬 적은 것을 확인할 수 있다.

YOLO가 배경 예측 실수를 덜 한다는 점을 이용해 이와 같은 잘못된 예측을 지우기 위해 YOLO를 사용하면 확실한 성능의 개선을 보여준다. 또한 YOLO가 워낙 빨라 기존 Fast R-CNN에 비교해 속도가 떨어지지도 않는다.
참고문헌
https://prowiseman.tistory.com/entry/논문-리뷰You-Only-Look-Once-Unified-Real-Time-Object-Detection [ProWiseman:티스토리] .



