출처 : https://arxiv.org/abs/2309.09530
Adapting Large Language Models to Domains via Reading Comprehension
We explore how continued pre-training on domain-specific corpora influences large language models, revealing that training on the raw corpora endows the model with domain knowledge, but drastically hurts its prompting ability for question answering. Taken
arxiv.org
대규모 언어 모델의 도메인 적응
이 논문의 제목은 "Adapting Large Language Models to Domains via Reading Comprehension / 읽기 이해를 통한 대형 언어 모델의 도메인 적응"으로, 다이쉬안 청(Cheng Daixuan) 외 두 명의 저자가 작성했으며, 2023년 9월 18일에 제출되었고 2024년 7월 25일에 마지막으로 수정되었다.
Abstract
- 이 논문은 대규모 언어 모델을 특정 도메인(예: 의학, 금융, 법률)에 맞게 적응시키는 방법을 탐구
- 구체적으로는 프롬프트 엔지니어링 "원본 코퍼스를 읽기 이해 텍스트로 변환"하는 방법을 통해 도메인 지식을 모델에 주입하는 방법을 제안한다.
이 논문은 도메인 특화 코퍼스(데이터셋)로 추가 학습을 진행할 때 대형 언어 모델(LLM)에 어떤 영향을 미치는지를 탐구한다.
연구에 따르면, 원본 코퍼스에서 학습을 하면 모델이 도메인 지식을 습득하게 되지만, 질문에 답하는 능력, 즉 프롬프팅(prompting) 능력은 크게 저하된다.
저자들은 원본 코퍼스를 읽기 이해 텍스트로 변환하는 방법을 제안한다.
- 각 원본 텍스트는 그 내용과 관련된 task들로 강화되며, 이를 통해 모델의 성능이 크게 향상됨
- 확장성이 뛰어남 : 생의학, 금융, 법률( biomedicine, finance, law) 등 3개 도메인에서 다양한 작업을 수행할 때 일관되게 성능을 개선
- 성능 향상 높음 : 7B 크기의 언어 모델이 큰 규모의 금융 도메인 특화 모델(BloombergGPT-50B)과 경쟁할 수 있는 성능을 달성함
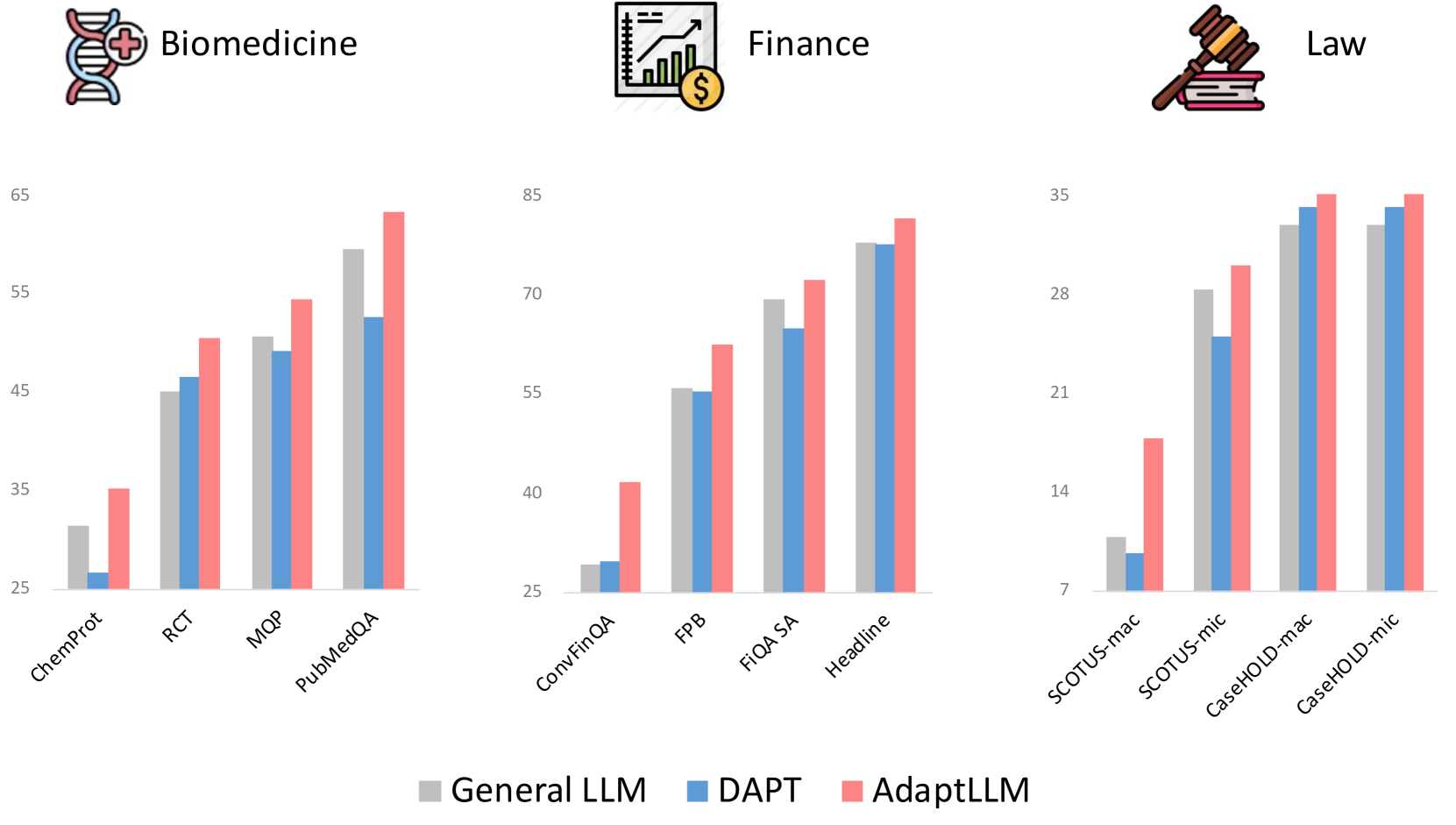
그림 1 :생물의학, 금융 및 법률 분야의 도메인별 작업 수행.
▶ General LLM : 일반 언어 모델
▶ DAPT : 일반 언어 모델에 DAPT (Gururangan et al.,2020)은 도메인별 원시 코퍼스를 사용하여 일반 모델을 계속 학습
▶ AdaptLLM : 원시 코퍼스 기반해 구성된 도메인 특화 읽기 이해 텍스트로 일반 모델을 계속 학습
또한, 도메인 특화된 읽기 이해 텍스트가 일반적인 벤치마크에서도 모델의 성능을 개선할 수 있음을 보여, 더 많은 도메인에서 활용 가능한 일반 모델을 개발할 잠재력이 있음을 시사한다.
1. Introduction
도메인 특화된 대형 언어 모델의 기존 학습 방법
도메인 특화된 대형 언어 모델의 기존 학습 방법들은 크게 세 가지 접근법으로 분류될 수 있다.
| 도메인 특화 코퍼스로 모델 재학습 | 특정 도메인의 데이터와 일반 데이터를 혼합해 모델을 처음부터 학습시키는 방식 | 직관적 / 막대한 비용 |
| 지도 학습을 통한 Fine-tuning | 특정 도메인의 데이터로 모델을 미세 조정하는 방식. | 좀 더 비용 효율적 / 도메인 지식을 충분히 얻지 못할 수 있음. |
| 지식 검색을 통한 프롬프트 | 도메인 지식을 검색하여 일반 언어 모델에 프롬프트하는 방식. | 모델 자체를 개선하지 않고 응용하는 방식 |
(1) 도메인 특화된 코퍼스 + 일반 코퍼스를 혼합 → 모델을 처음부터 학습시키는 방식 (Wu et al., 2023b)
이 방식은 직관적으로 도메인 특화된 LLM을 생성할 수 있지만, 막대한 계산 및 데이터 요구 사항으로 인해 큰 우려가 제기됨.(Yang et al., 2023; Ling et al., 2023).
(2) 지도 학습 데이터셋을 사용해 언어 모델을 미세 조정하는 방식 / fine-tunes the language model using supervised datasets
(Singhal et al., 2022; 2023; Li et al., 2023b; a; Wang et al., 2023; Han et al., 2023; Xiong et al., 2023; Huang et al., 2023).
이 방식은 비용 효율적이지만, 미세 조정된 LLM이 도메인 지식을 얼마나 잘 습득하는지에 대한 의문이 존재함.(Zhou et al., 2023; Gudibande et al., 2023).
(3) 일반 언어 모델에 도메인 지식을 검색해 제공하는 방식 / prompts the general language model with retrieved domain knowledge (Li et al., 2023b; Cui et al., 2023; Huang et al., 2023)
이는 LLM을 직접적으로 향상시키는 것보다는 LLM의 응용으로 볼 수 있음.
이러한 도메인 특화된 코퍼스에서의 지속적인 사전 학습(Continued pre-training on domain-specific corpora),
즉 도메인 적응 사전 학습 DAPT (domain-adaptive pre-training은 다양한 자연어 이해 모델(Devlin et al., 2019; Liu et al., 2019; Clark et al., 2020)을 특정 도메인에 적응시키는 데 효과적인 것으로 입증되었다(Yao et al., 2021; Gururangan et al., 2020; Cheng et al., 2022).
✅DAPT(Domain-Adaptive Pretrain)란?
- LLM을 수행하고자 하는 도메인에 맞게 사전학습하는 것 , 모델을 Domain - specific한 모델로 만드는 방법
언어 모델이 일반적인 능력을 유지하면서 도메인 특화된 지식을 통합하였고,
파인튜닝보다 적은 비용으로 도메인 특화된 다운스트림 작업에서 좋은 성능을 보였음
그러나 도메인 적응 사전 학습이 대규모 생성 모델에서는 프롬프팅 성능에 급격한 하락을 초래했다.
AdaptLLM(Adapted Large Language Model) 제시
도메인 적응 사전 학습이 LLM에 도메인 지식을 부하지만, 프롬프팅 능력을 저하시킨다는 점을 어떻게 해결할까?
본 논문에서는 도메인 특화 지식을 활용하면서 프롬프팅 성능을 향상시키기 위해, 대규모 원본 코퍼스를 읽기 이해 텍스트로 변환하는 방법을 소개하였고 이 결과 모델을 AdaptLLM(Adapted Large Language Model)라는 이름으로 제시했다.
저자는 다양한 도메인에서 실험을 진행한 결과, 프롬프팅 능력을 해치지 않으면서 특정 도메인(생의학, 금융, 법률)에 특화되도록 모델 성능을 향상시키는 AdaptLLM의 효과를 확인하였다.
1) 원본 텍스트는 그 내용과 관련된 Task들로 보강되며, 이는 모델이 원본 텍스트의 맥락을 기반으로 자연어로 질문에 답할 수 있는 능력을 유지하도록 설계됨(아래 예시 참고) ⇒ 도메인 특화 능력 보강
2) 읽기 이해 텍스트를 다양한 일반 지시(genernal instruction)로 보강하여 프롬프팅 능력을 더욱 향상시킴(Wei et al., 2022; Zhou et al., 2023; Xu et al., 2023; Mukherjee et al., 2023) ⇒ 프롬프팅 저하 방지
예를 들어, 의료 도메인에서는 '환자의 증상과 진단 결과를 바탕으로 적합한 치료법을 제안하시오'가 특정 도메인의 instruction 라면, "이 텍스트에서 중요한 내용을 요약하시오."는 일반 지시(genernal instruction)임
[ 도메인 특화된 읽기 이해 텍스트 변환 예시 ]
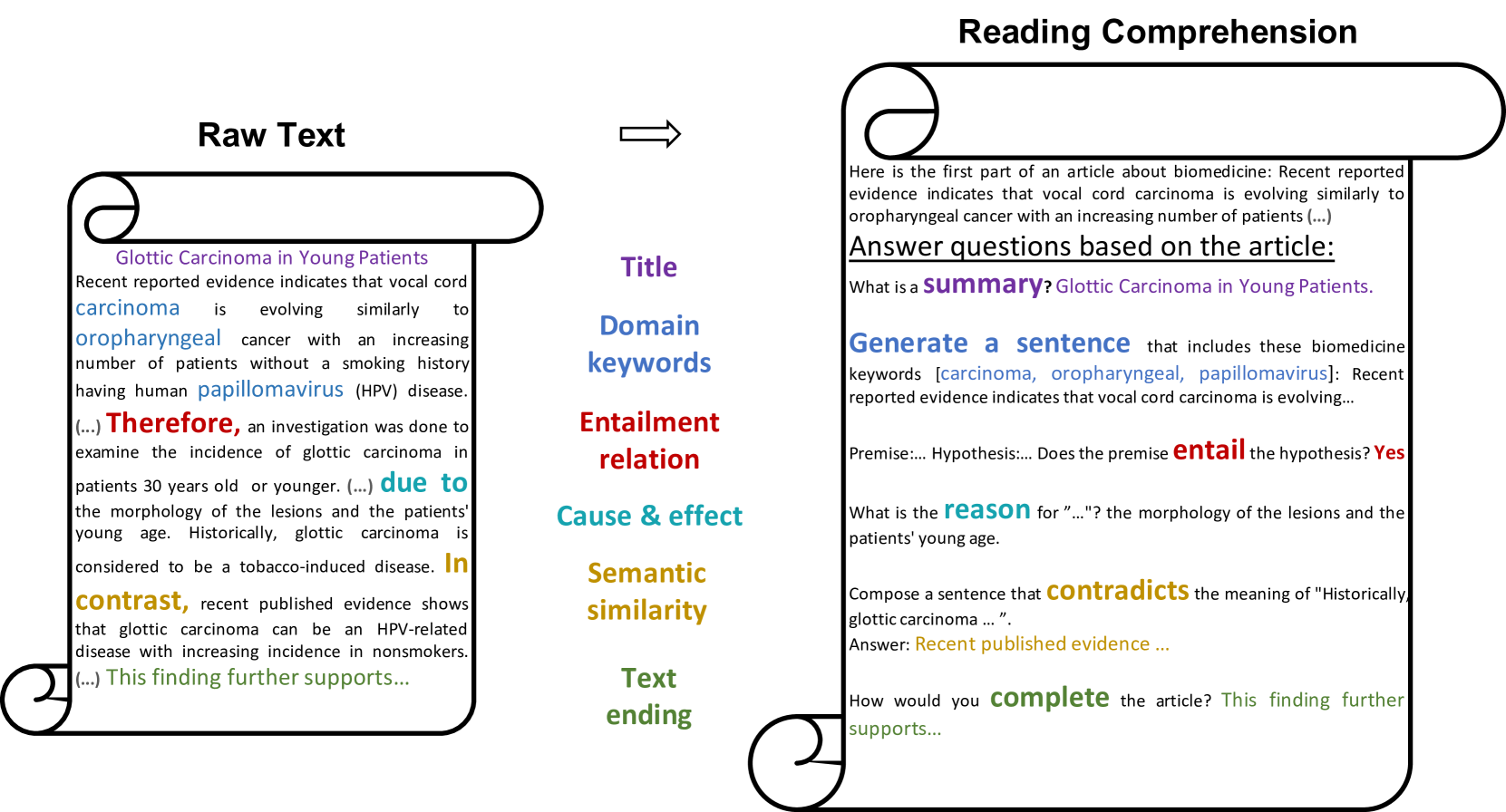
| Summarization (purple) - 요약 | 요약하는 작업 |
| Word-to-Text (blue) - 단어 > 텍스트로 변환 | 단어를 텍스트로 변환하는 작업 |
| Natural Language Inference (red) - 자연어 추론 | 두 개의 문장이 있을 때, 한 문장이 다른 문장에 대해 참인지 거짓인지, 혹은 상관없는지 추론하는 작업 |
| Commonsense Reasoning (teal) - 상식적 추론 | 직관적이고 일상적인 상식에 기반하여 추론하거나 결정을 내리는 작업 예) 문장 이해: "비가 오고 있다, 우산을 챙겨라."라는 문장에서 비가 오면 우산이 필요하다는 상식을 모델이 이해 상황 판단: "물이 끓고 있다면 매우 뜨겁다."는 물리적 세계에 대한 상식적인 추론 원인과 결과: "빵을 굽다가 시간이 너무 지나면 빵이 탄다."는 상식적인 결과 예측 |
| Paraphrase Detection (yellow) - 문맥적 유사성 | 두 문장이 서로 다른 표현을 사용하고 있지만 같은 의미를 전달하는지 확인하는 작업 예) 두 문장은 의미가 같음 문장 1: "그는 차를 운전해서 집에 갔다." 문장 2: "그는 집으로 차를 몰았다." |
| Text Completion (green) - 텍스트 완성 | 부분적인 텍스트 기반으로 나머지 문장 예측해서 완성하는 작업 예) (입력)오늘 날씨는 정말 → (출력) 좋아서 기분이 좋다 |
2. Related Work
2.1. DAPT
Domain Adaptive Pre-Training (이하 DAPT)
- 언어 모델의 기존 사전학습 방식인 Next Token Prediction을 이어 나가는 방식
LLaMA 모델을 biomedicine, finance, law 세 개 도메인 텍스트에 DAPT한 결과를 기존 LLM과 비교합니다.

DAPT를 통해서 각 도메인에 대한 지식이 확장되었음은 확실하지만, 반대로 Prompting 관련 능력이 소폭 하락한 것으로 확인됩니다. 이러한 문제점을 해결하기 위한 방식에 대한 연구 내용이 이 논문의 핵심 포인트라고 볼 수 있겠습니다.
2.2. Training from Scratch
finance 도메인에서 LLM을 scratch부터 학습하여 뛰어난 성능으로 주목을 받은 모델 중 BloombergGPT가 아주 유명합니다.
오직 이 분야를 잘 처리하기 위해 만든 모델이 무려 50B 사이즈를 자랑하니 얼마나 많은 공수가 들었을지 가늠이 잘 안됩니다.
그런데 결국 비용이 너무 많이 들어가다 보니 효율적인 방식이 아닙니다.
업데이트도 비효율적
2.3. Instruction Fine-tuning
question-answer 형식을 따라 학습하는 것으로 알려진 이 학습법은 아마 LLM 학습 방식 중 가장 사랑받는 것이 아닐까 싶습니다.
PLM을 직접 만들 필요도 없지만 학습 효과가 굉장히 뛰어나죠.
대신 특정 도메인에 특화시키는 것이 꽤 까다롭습니다. 학습에 필요한 데이터를 확보하기가 어렵기 때문입니다.
특히나 모델이 클수록 많은 양으 instruction fine-tuning 데이터가 요구되는데 특정 도메인 내에서 question-answer 형식을 갖춰 대량의 데이터셋을 구축하기란 쉽지 않은 일입니다.
✅ Instruction Tuning 방법론이란?
파인튜닝 시 모델을 특정 데이터셋으로 학습 시키는 방법처럼 question-answer 형식의 데이터셋을 통해 모델이 학습되는 방식
데이터셋의 구성이 사용자의 구체적인 지시(instruction)와 이에 대한 모델의 적절한 응답(output)으로 구성
예를 들면, "김치찌개 끓이는 법을 알려줘" 라는 지시(instruction)에 대한 응답으로 "물 몇cc, 돼지고기 몇그람, 두부 반모.. 끓이는 순서는.." 이런 레시피로 답변(output) 셋 구성
2.4. Retrieval-augmented Prompting (RAG)
언어 모델을 직접 학습하지 않고도 특정 도메인의 지식을 활용할 수 있도록 해주는 방법입니다.
처음에는 hallucination을 줄이기 위한 방법으로 많이 활용되었으나 지금은 모델의 능력과 지식을 확장하는 방식으로 널리 쓰이고 있습니다. 이 연구에서 중요하게 다루고 있는 내용은 아닙니다.
3. 제안하는 방법: 읽기 이해 텍스트 변환 Reading Comprehension ⭐
- 도메인별 원시 코퍼스에서 LLM을 계속 학습하는 것 대신 원시 코퍼스를 읽기 이해 텍스트(reading comprehension text)로 변환하고 ,변환된 데이터를 사용해 모델을 조정합니다.
- 읽기 이해 텍스트의 구성 : [ 원시 텍스트 + 그 내용에 관련된 과제 ]
- 본 논문에서 제시하는 모델 학습 방식은 크게 두 단계로 나뉩니다. raw text를 "읽는(reading)" 단계와 이 내용을 "이해(comprehension)"하는 단계입니다.
- 읽는(reading) 단계는 원시 텍스트에 대한 모델 훈련 단계를 뜻한다.
- 이해(comprehension) 단계는 간련 task에 대한 지속적인 훈련을 의미한다. 이는 question-answering 형식을 따르고 있는데, 이는 input question에 대해 답하는 능력(prompting)을 따르도록 하기 위함입니다.
3.1 읽기 이해 텍스트를 생성하는 방법 Creating Reading Comprehension Texts
정규 표현식을 기반으로 원본 코퍼스(데이터) 에서 intrinsic tasks을 자동으로 추출하는 마이닝 기법 사용합니다.
데이터 채굴(Mining Patterns)을 통해 원시 코퍼스에서 자동으로 학습용 데이터를 추출하고, 이 데이터를 사용해 사전 학습된 모델(Pre-trained Model)을 미세 조정하여, 다양한 NLP 과제에서 성능을 높입니다.
정규표현식 기반으로 원시 텍스트 코퍼스에서 자연스럽게 발생하는 작업을 자동으로 추출합니다.
intrinsic tasks를 mining하고 이를 모델에 fine-tuning 하여 zero-shot 성능을 높이는 방식입니다.
이는 미리 준비된 데이터셋이 아니라, 원시 코퍼스 내에서 자동으로 만들어지는 문제 유형을 말합니다.
예를 들어, 문장 간의 관계나 텍스트 요약 작업 등이 포함됩니다.
를 통해 모델이 제로샷(Zero-shot) 환경에서도 성능을 높일 수 있도록 훈련합니다.
pretraining corpora에 존재하는 intrinsic tasks를 획득하기 위한 방법은 이전 연구의 것을 따르고 있습니다.
(Kar et al. 2022, EMNLP 2022 main, https://aclanthology.org/2022.emnlp-main.509/)
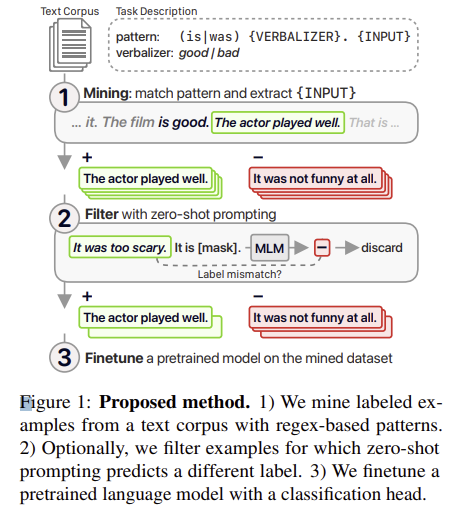
- Mining (데이터 채굴): 텍스트 코퍼스에서 정규식 패턴을 이용해 데이터를 추출합니다.
- 그림에서는 텍스트 패턴이 (is|was) {VERBALIZER}. {INPUT}인 것을 볼 수 있습니다. 문장 내에서 "is"나 "was" 뒤에 특정 평가 형용사("good", "bad")가 오고, 그 뒤에 평가받는 대상(문장이나 구)이 있는 패턴을 찾는 것입니다.
- 여기서 {VERBALIZER}는 "good"이나 "bad"와 같은 단어로 대체되고, {INPUT}은 평가 대상 문장이 됩니다.
- 예를 들어, "The actor played well."이라는 문장은 긍정적으로 분류되고, "It was not funny at all."은 부정적으로 분류됩니다.
- Filter with zero-shot prompting (제로샷 프롬팅을 사용한 필터링): 제로샷 프롬팅으로 잘못된 레이블을 가진 데이터를 필터링합니다.
- 문장이 “It was too scary.”일 때, 모델이 그 문장의 감정이나 성격을 잘못 예측할 경우(MLM 마스킹을 통해) 이를 필터링하고 제거합니다.
-
✅ MLM 마스킹(Masked Language Model)
특정 단어를 가리고(masking) 그 빈자리를 모델이 추론하는 방식의 학습 기법
- Finetune (모델 미세 조정): 필터링된 데이터를 사용해 사전 학습된 모델을 미세 조정해 분류 성능을 향상시킵니다
위의 연구방법을 응용해 본 연구에서 추출하는 task를 종류별로 정리한 표는 아래와 같습니다.
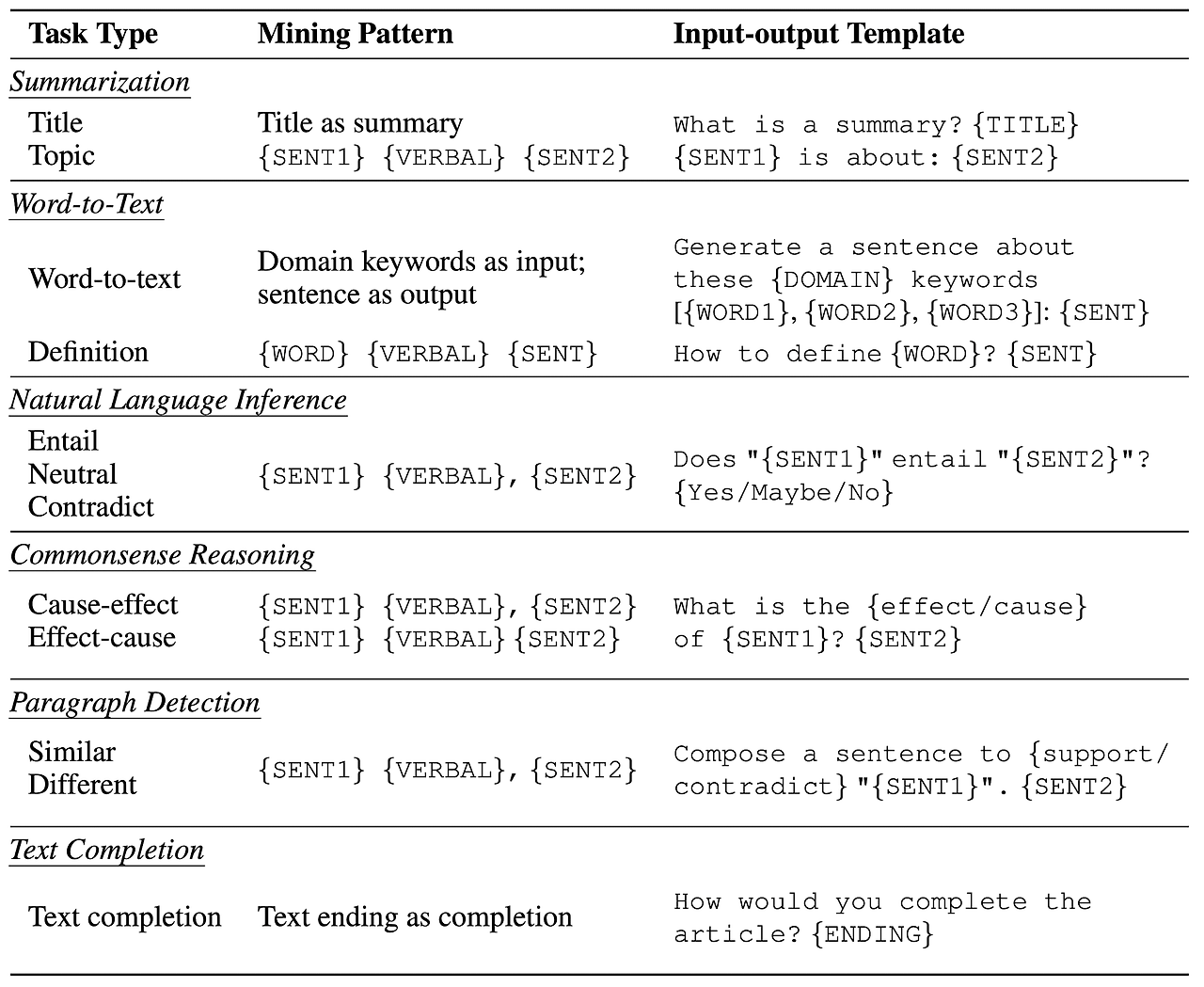
3.1.1. Summarization
모델이 주어진 텍스트를 요약하도록 하는 태스크입니다.
예를 들어, 요약 과제는 "What is a summary? {TITLE}"과 같은 템플릿을 사용하고, 자연어 추론 과제는 두 문장 간의 관계를 묻는 템플릿을 사용합니다.
여기서는 텍스트를 보고 제목을 맞히도록 하는 것과 동시에 반대로 제목을 보고 article을 작성해보도록 하는 것도 태스크로 사용하게 됩니다.
3.1.2. Word-to-Text
일부 키워드를 바탕으로 문장을 생성하는 태스크입니다.
특정 도메인과 관련된 vocabulary를 구축하기 위해 SentencePiece tool을 사용했다고 합니다.
raw text의 각 문장을 보고, domain-specific 단어가 세 개 이상인 문장을 Word-to-Text 데이터셋으로 사용합니다.
이를 응용하면 텍스트 내에 존재하는 특정 도메인과 관련된 단어를 추출하도록 만들 수도 있습니다.
예를 들어, 입력으로 "neuron, synapse, brain" 같은 생물학적 용어를 주고, "Generate a sentence about these {DOMAIN} keywords"라고 요청하면, 모델은 "Neurons communicate through synapses in the brain."와 같은 문장을 생성할 수 있습니다.
3.1.3. Natural Language Inference
두 개의 문장을 대상으로 둘의 관계를 premise-hypothesis로 보고, 후자가 전자에 entailment 되는지 contradictory 일지 판단하는 태스크입니다.
이를 위해서 Therefore와 같은 연결어를 사이에 두고 있는 문장들은 'Entailment'(포함)로, However과 같은 연결어를 사이에 두고 있는 경우엔 'Contradictory'(모순)로 라벨링 합니다.
3.1.4. Common Sense Reasoning
"What is the reason of {SENT1}? {SENT2}" 와 같이 cause-and-effect logic(원인, 결과 간의 관계)을 갖추도록 하는 태스크입니다.
예를 들어, 입력 문장: "She left the window open."일 때, 모델에게 "What is the effect of 'She left the window open'?"라고 묻습니다. 모델의 출력은 "The room became cold." (창문을 열어둔 결과로 방이 추워졌다).이 될 것입니다.
3.1.5. Paraphrase Detection
두 개의 문장이 의미적으로 동일한지 아닌지를 확인하는 태스크입니다.
여기서도 정규표현식 기반이고 특정 키워드(연결어)를 바탕으로 태스크를 추출한 것으로 보입니다.
그러나 일부 단어(Similarly)는 애매해서 두 문장이 의미적으로 동일하지 않은 경우도 존재한다고 합니다.
그래서 이를 한 문장이 다른 문장의 의미를 'support' 하는지 그렇지 않은지('different') 설명하는 태스크로 전환했습니다.
3.1.6. Text Completion
말 그대로 주어진 문장의 텍스트를 완성하는 태스크입니다.
주어진 텍스트 이후에 올 말을 알맞게 예측하면 됩니다.
이 태스크의 장점은 mining 이 필요하지 않다는 것입니다.
예를 들어, 시작 문장: "After a long day at work, John decided to relax by"가 있을 때, 모델에게 "How would you complete the article?"라고 요청하면, 모델의 출력: "watching his favorite movie."이 됩니다.
3.2. 도메인 특정 작업 및 데이터 혼합 Mixing with General Instructions
본 연구에서 제시하는 방식만으로는 현실에 존재하는 다양한 태스크를 커버하는 것이 당연히 불가능합니다.
따라서 일반적인 instruction을 일정 비율로 포함하는 것이 더 좋은지를 확인한 결과도 포함되어 있습니다.
이 논문에서는 특정 도메인에 맞는 작업을 수행하기 위해, 일반 지침(general instructions)과 도메인 특화된 데이터를 혼합합니다. 예를 들어, 생물의학 도메인에서는 PubMed Abstracts와 같은 전문 코퍼스를 사용하고, 법률 도메인에서는 법률 관련 텍스트를 사용해 사전 학습된 모델을 미세 조정합니다.
이와 같은 방식으로, 각 도메인에 맞는 작업을 학습하고 적용할 수 있게 합니다.
4. Experiment
4.1.1. Domain-adaptive Pre-training
Pile 데이터셋의 PubMed Abstracts & FreeLaw Opinion을 pre-training corpora로 사용합니다.
fiance 관련해서는 FinGPT의 코드 베이스를 사용하여 7천 개에 달하는 금융 뉴스를 수집했다고 합니다.
일반적인 instruction을 위해서는 LIMA, WizardLM, Orca 등을 사용했습니다.
실험은 LLaMA-7B 모델을 기준으로 진행했습니다.
4.1.2. Creating Reading Comprehension Texts
챕터 2에서 정리한 양식에 맞는 데이터셋을 사용합니다.
이때 특정 태스크가 지나치게 많이 등장하는 것을 방지하기 위해서 각 raw text에 대해 한 태스크가 최대 두 번만 추출될 수 있도록 제한합니다.
4.1.3. Domain-specific Tasks
- biomedicine
- PubMedQA, ChemProt, MQP, RCT, USMLE
- finance
- BloombergGPT, ConvFinQA, FPB, FiQA SA, Headline, NER
- law
- SCOTUS, CaseHOLD, UNFAIR-ToS, LexGLUE
4.2. Results
- 실험 도메인: 의학, 금융, 법률.
- 결과: 제안된 방법(AdaptLLM)은 기존 방법(DAPT)보다 도메인 특정 작업에서 일관되게 더 나은 성능을 보였습니다. 또한 일반적인 벤치마크에서도 성능 향상을 보여 다양한 도메인에 적용할 수 있는 가능성을 보였습니다.
- 단순히 raw text로 continued pre-training을 했을 때에 비해 성능이 뛰어나다는 결과를 보여주고 있습니다.


언급된 세 개의 도메인에서 대표적인 베이스라인은 회색으로, 본 논문의 방법론을 적용한 AdaptLLM은 빨간색으로 표시되어 있습니다.
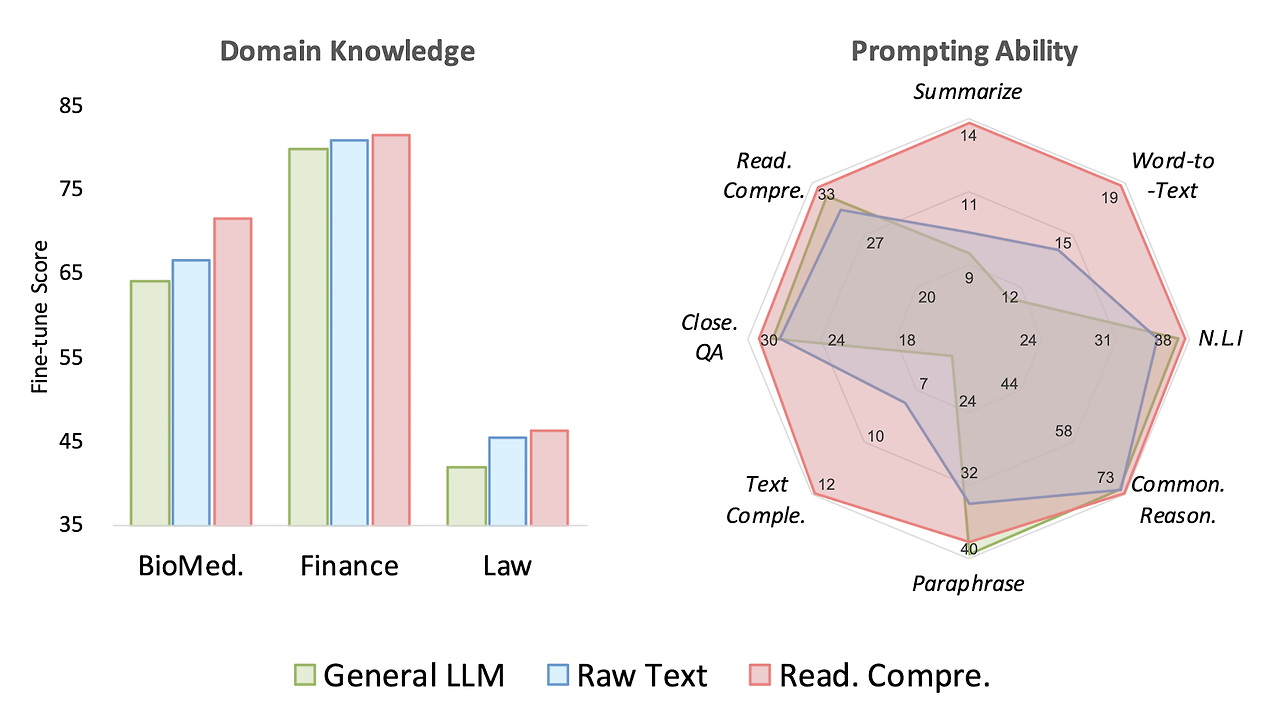
제일 기본이 되는 사전학습 모델은 초록색으로, 여기에 raw text를 이용하는 DAPT를 적용한 것은 파란색으로 표시되어 있습니다.
DAPT만 적용하더라도 성능의 향상이 소폭 있으나, domain 관련 knowledge를 습득하는 데 있어서 본 논문에서 제시하는 방식이 더욱 효과적이라는 것이 확인됩니다.
게다가 그림의 오른쪽을 보면 상대적으로 훨씬 뛰어난 prompting ability를 지녔다는 것 또한 할 수 있습니다.
기존 LLM과 DAPT 버전이 약세를 보이는 Summarize, Word-to-Text, Text Completion 태스크들은 주로 instrcution tuning과 같은 형식의 학습 방식에 크게 영향을 받는 것으로 보입니다.
즉, 단순히 다음 토큰을 예측하는 방식으로 얻어진 지식만으로는 수행하기 어려운 태스크라는 뜻이죠.
추가 시사점
- 여기서는 기존 corpora에서 task를 추출하기 위해 정규표현식 기반의 방법론을 사용했는데 여기에 많은 한계점이 존재할 거라고 생각이 들었습니다.instruction tuning을 수행할 땐 최대한 다양한 종류의 태스크를 포함해야 한다는 것은 이미 잘 알려져 있으므로, 이를 위한 데이터셋을 만든다고 한다면 규칙 기반의 방법론보다는 모델 기반의 방법론이 더 효율적이지 않을까 하는 생각이 들었습니다.
- 당연하게도 raw text에서 일관된 패턴과 규칙만으로 태스크를 추출하게 되면 모델이 학습할 수 있는 내용들이 너무 적을 것이고, 그렇기 때문에 일반적인(general) instruction tuning 데이터와 함께 섞어서 학습한 것이 더 좋은 효과를 보였을 것이라는 생각이 듭니다.
- 한 가지 더 생각해 볼 수 있는 것은 본 연구에서와 달리 모델을 활용하여 task를 추출하는 것입니다.
참고 자료
<Continual Learning> Adapting Large Language Models to Domains via Reading Comprehension (2023.09, ICLR 2024)
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️usechatgpt init success[Microsoft, BIGAI]- raw corpora로 continued pre-training을 수행
chanmuzi.tistory.com



