NLP논문 Sequence to Sequence Learning with Neural Networks 논문을 읽고 정리한 내용입니다
1. Introduction
- 심층 신경망(DNNs)은 음성 인식 및 시각 객체 인식과 같은 어려운 문제에 대한 탁월한 성능을 달성하는 매우 강력한 기계 학습 모델
- 적은 수의 단계로 임의의 병렬 계산을 수행
- 예) 2개의 2차 크기의 숨겨진 레이어만 사용하여 N개의 N비트 숫자를 정렬할 수 있는 능력
- 신경망은 기존의 통계 모델과 관련이 있지만 복잡한 계산을 학습
- 벨이 지정된 교육 세트가 네트워크의 매개 변수를 명시하는 데 충분한 정보를 가지고 있을 때 큰 DNNs는 지도된 역전파를 사용하여 훈련
- 문제 : DNNs는 입력 및 대상이 고정 차원의 벡터로 합리적으로 인코딩 될 수있는 문제에만 적용 ( input size가 fixed된다는 한계점 sequencial problem을 제대로 해결할 수 없다 )
- 해결 : 논문에서는 2개의 LSTM (Long Short Term Memory)을 각각 Encoder, Decoder로 사용해 sequencial problem을 해결
- 아이디어는 입력 시퀀스를 한 번에 한 타임 스텝씩 읽기 위해 하나의 LSTM을 사용하여 대형 고정 차원 벡터 표현을 얻은 다음 다른 LSTM을 사용하여 그 벡터에서 출력 시퀀스를 추출
- 두 번째 LSTM은 본질적으로 입력 시퀀스에 종속된 반복 신경망 언어 모델
- LSTM의 장기적인 시간 종속성에 성공적으로 학습 할 수있는 능력 때문에 이 응용 프로그램에 대한 자연스러운 선택으로 만드는 것
- 주요 결과
- WMT'14 영어에서 프랑스어로 번역 작업에서 우리는 깊은 LSTM 5 개의 앙상블에서 직접 번역을 추출하여 간단한 좌에서 우로 빔 검색 디코더를 사용하여 34.81의 BLEU 점수 => 대규모 신경망을 사용한 직접 번역의 최고 결과 ( SMT 기준선의 BLEU 점수는 33.30 )
- LSTM을 사용하여 동일한 작업의 SMT 기준선의 공개적으로 사용 가능한 1000 최상의 목록 점수 36.5의 BLEU 점수(3.2 BLEU 점수로 개선)
- SGD는 긴 문장에 문제가 없는 LSTM을 학습
- long sentence/ 단어를 역순으로 배치하는 방식에서 더 큰 성능 상승 폭을 보임
- LSTM을 활용한 효율적인 Seq2Seq 기계 번역 아키텍쳐를 제안
- 통계적 언어 모델에서 딥러닝 기반의 모델로 전환의 기반이 된 논문
2. Model
1) Seq2Seq 모델 구조

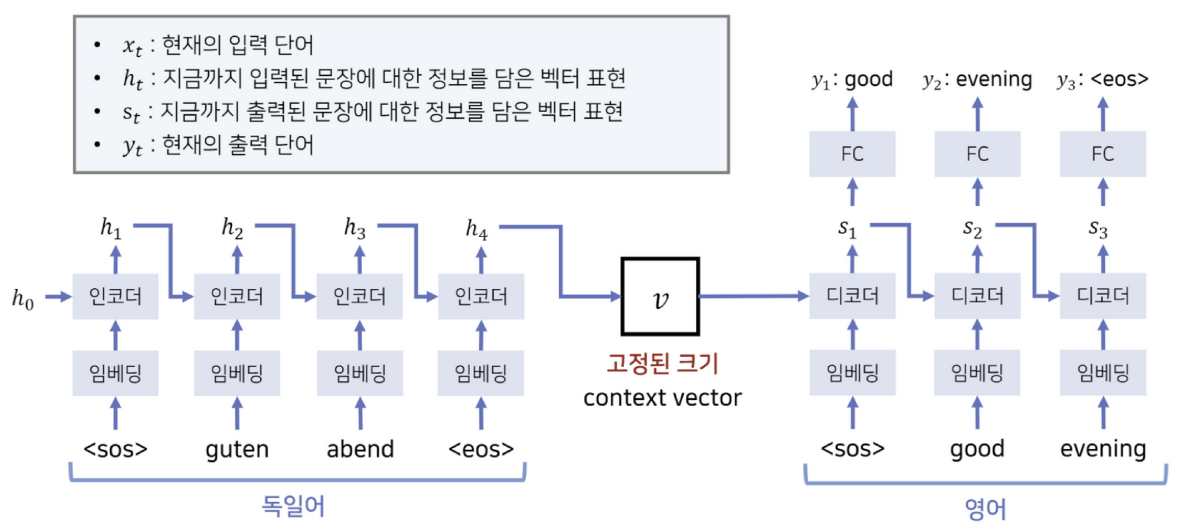
- 보라색 : 가장 최근 시점 hidden state 값이 들어감 -> 디코더로 들어가기전 Context vector 그 자체가 된다
문제 : RNN은 기본적으로 sequencial problem에 매우 적절한 model 그러나 input size와 output size가 다른 경우에 대해서는 좋은 성능을 보일 수 없었음
해결 : 논문에서 제시하는 model은 Encoder LSTM에서 하나의 context vector를 생성 + Decoder LSTM에서 context vector를 이용해 output sentence를 생성하는 방식으로 RNN의 한계점을 극복하고자 함
- input과 output sentence 간의 mapping을 하는 것이 아닌, input sentence를 통해 encoder에서 context vector를 생성하고, 이를 활용해 decoder에서 output sentence를 만들어냄
- Encoder LSTM의 output인 context vector는 Encoder의 마지막 layer에서 나온 output이다. 이를 Decoder LSTM의 첫번째 layer의 input으로 넣게 된다.
- 여기서 주목할만한 점은 input sentence에서의 word order를 reverse해 사용했다는 것이다. 또한 (End of Sentence) token을 각 sentence의 끝에 추가해 variable length sentence를 다뤘다.
2) 모델 원리
- RNN은 입력 시퀀스에서 출력 시퀀스를 계산하는 데 사용되는데, 입력과 출력의 길이가 다르고 복잡한 관계를 가지는 문제에는 적용하기 어렵습니다.
- LSTM은 장기적인 시간 종속성을 학습할 수 있기 때문에 이러한 상황에서 성공할 수 있습니다.
- LSTM은 입력 시퀀스의 고정 차원 표현을 계산하고, 이를 사용하여 출력 시퀀스의 확률을 계산합니다.
- 모델은 입력 및 출력 시퀀스에 대해 각각 다른 LSTM을 사용하며, LSTM의 층 수를 늘리고 입력 문장의 단어 순서를 반대로 변경합니다.
- 단순한 데이터 변환으로 입력과 출력 간의 통신을 용이하게 만들어 성능을 향상시킵니다.
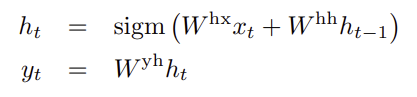

3. Experiments
WMT’14의 English to French dataset으로 실험을 진행했다. source / target language 각각에 fixed size vocabulary를 사용했다 (source: 160,000 / target: 80,000). OOV는 “UNK” token으로 대체된다. long sequence에서는 source sentence를 reverse시킨 경우가 특히나 성능이 더 좋았다. 구체적인 수치로 BLEU score가 25.9에서 30.6으로 증가했다.
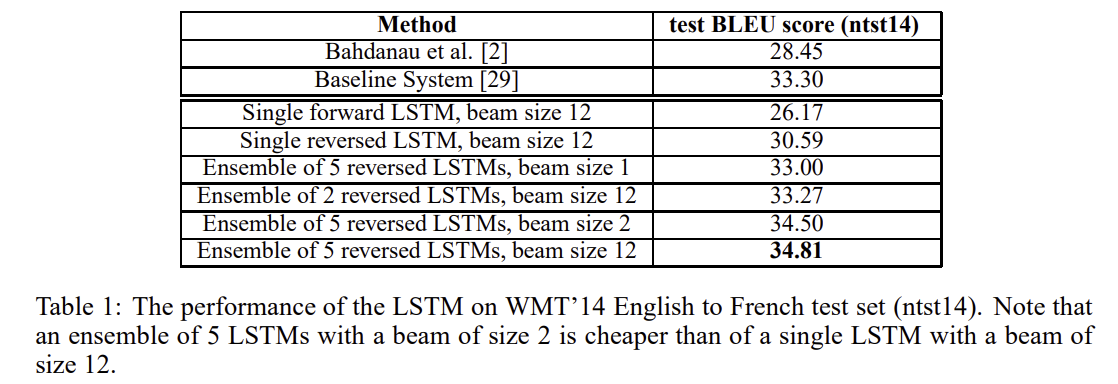

- 케이스 블루 점수를 사용하여 번역 품질을 평가
- LSTM 앙상블을 통해 우수한 결과를 얻었으며, 초기화와 미니 배치의 무작위 순서에 차이를
- 구문 기반 SMT 기준선을 처음으로 능가하는 순수한 신경 기반 번역 시스템의 성과를 달성함.
[ 참고자료 ]
https://cpm0722.github.io/paper-review/sequence-to-sequence-learning-with-neural-networks
[NLP 논문 리뷰] Sequence To Sequence Learning With Neural Networks (Seq2Seq)
Paper Info
cpm0722.github.io
14-01 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
이번 실습은 케라스 함수형 API에 대한 이해가 필요합니다. 함수형 API(functional API, https://wikidocs.net/38861 )에 대해서 우선 숙지 후…
wikidocs.net
https://blog.naver.com/sooftware/221784419691
[Sooftware 머신러닝] Seq2seq (Sequence to sequence)
Machine Learning: Seq2seq (Sequence to sequence) "Sooftware" 이 글은 제가 공부하여 이...
blog.naver.com



