GPT-1은 OpenAI에서 Improving Language understandingby Generative pre-Training (2018년) 논문에서 공개된 Transformer의 decorder만 활용한 자연어 모델입니다. 해당 글은 이 논문의 리뷰입니다.
논문 원문 : GPT-1 (https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
1 Introduction
1. 첫 번째 섹션 : 기존의 자연어 처리 방법, 그것들이 겪는 주요한 문제점들에 대해 논의
- 기존 모델들의 제한된 문맥 이해와 처리 능력, 그리고 복잡한 작업에 대한 어려움 등이 여기에 포함
- 이러한 문제들은 자연어 처리 작업의 효율성과 정확성을 제한하며, 이를 해결하기 위한 새로운 접근 방법의 필요성을 높입니다.
2. 두 번째 섹션 : GPT-1의 핵심인 모델 구성과 학습 방법
- 이 부분은 GPT-1의 기본적인 작동 원리를 이해
- GPT-1이 어떻게 고급 자연어 처리를 하게 되었는지에 대해 서술
3. 세 번째와 네 번째 섹션 : GPT-1의 실험 결과와 분석 실험에 대해 소개
- GPT-1의 성능과 그 한계를 실제로 확인
4. 다섯 번째 섹션에서는 GPT-1의 장단점을 살펴봅니다. 모델의 강점과 약점을 이해
6. 마지막 섹션에서는 GPT-1의 의의
- GPT-1이 자연어 처리 분야에 어떤 영향을 미치고 있는지, 그리고 앞으로 어떤 발전이 기대되는지
2 Related Work
- 문제는 기존 언어 모델에서 이렇게 다량의 Unlabeled Data를 충분히 활용할 수 있는 방법이 없다는 것
- Down Stream Task 중에서 Supervised learning(지도학습 - label존재 / 회귀+분류)은 함수를 찾기 위해 labeled dataset을 사용 → unlabeled dataset을 어떻게 사용해야할까?
- ELMo와 비슷한 배경 → 비정형데이터가 정형데이터보다 훨씬 많이존재
- ELMo는 unlabeled data를 pretrain하여 단어 수준의 정보에 활용
- 대표적인 feature-based approach 전이학습 기법 (※ feature-based approach : 임베딩은 그대로 두고 그 위의 layer만 학습)
- GPT-1 vs ELMo
- GPT는 fine-tuning을 통해 전이학습 진행
- GPT-1은 Transformer 디코더를 사용해 단방향 문맥을 고려 vs ELMo는 앙방향 LSTM을 사용해 문맥고려
- GPT는 Long-term despendency를 잘 학습시킴
- Byte-pair encoding(BPE) : 단어를 Tokenization하기 위한 방법
- Tokenization 이란 텍스트데이터를 인공지능모델의 입력으로 이용하기 전 적당한 단위의 서브워드로 쪼개는 것
- BPE는 텍스트 단축알고리즘 : 말뭉치에서 가장 많이 등장하는 바이트 쌍을 찾아내고 해당 바이트 쌍을 하나의 새로운 토큰으로 대체하는 과정을 반복하여 텍스트를 압축
-
- 어휘 집합과 토큰 시퀀스를 너무 크게 하지 않아 미등록 토큰 문제를 최대한 피할 수 있음
-
- GPT(BPE)에서는 subword-based tokenization사용
- character-based, subword-based, word-based 3가지가 존재
- GPT : BPE 사용 vs BERT : wordpiece사용
[예시] 단어 말뭉치 "low", "lower", "newest", "widest"
- 초기 상태에서는 모든 문자를 단일 토큰으로 간주
- ["l", "o", "w", "e", "r", "n", "w", "s", "t", "i", "d"]
- 가장 빈번하게 등장하는 바이트 쌍을 찾기
여기서는 "e"와 "s"가 가장 많이 함께 등장. 이 두 바이트 쌍을 하나의 토큰으로 대체- ["l", "o", "w", "er", "n", "w", "es", "t", "i", "d"]
- 다시 가장 빈번하게 등장하는 바이트 쌍을 찾아서 하나의 토큰으로 대체
- ["l", "o", "w", "er", "n", "w", "est", "i", "d"]
- 이 과정을 원하는 횟수만큼 반복. 예를 들어, 여기서는 세 번 반복
- 압축된 토큰 시퀀스를 살펴보면: ["low", "er", "n", "w", "est", "i", "d"]
텍스트의 크기를 줄임 + "newest"나 "widest"와 같은 희귀한 단어들도 이제는 바이트 단위로 분해되지 않고 처리
3 Framework
GPT : Generative Pre-Trained Transformer
- 대부분의 task들은 supervised learning을 기반으로 모델 학습시키지만, 이러한 labeled데이터를 얻는데에는 자원과 시간이 많이 쓰임
→ GPT-1모델은 [step1] pre-training : unlabeled data 라벨이 없는 데이터를 이용해 모델을 먼저 학습 시킴 + [step2] fine-tuning : 적은 양의 label 데이터를 이용해 fine-tuninig을 진행함으로써 target task에 대한 성능 향상
✅ 설명 순서
3-1. GPT-1의 전체 Architecture
3-2. Unsupervised Pre-Training
3-3. Supervised Fine Tuning
3-4. Task별 Input 구성 방법
3-1. Architecture
1. Encorder와 연결되는 부분을 제거한 Transformer모델의 Decoder만을 가져와서 사용한다.

- 🙆 Decoder만 사용한 이유는 ? Unsupervised learning을 하기 위해서
- 1) 다음단어를 예측하는 사전학습에 decorder가 더 적합함→ 디코더는 텍스트의 이전 부분을 입력으로 받아 이어지는 단어를 생성하는 데 사용
- 2) 모델 구조를 간결하게 만들기 위해서임→ 트랜스포머(Transformer)의 인코더-디코더 구조에서 인코더는 주로 입력 텍스트를 인코딩하는 데 사용
그러나 GPT 인코더가 필요하지 않으므로 모델의 구조가 더 간결 . encoder만큼의 파라미터 수가 줄어듦
- + BERT모델에서는 Transformer의 Encoder만을 사용함
- 🙆 근데 양방향을 사용하면 더 좋은 거 아닌가? NO.
transformer는 단방향 , 뒤에 이어지는 정보를 예측하기 위해서는 앞선 토큰들만 예측을 사용해야함
따라서 인코더도 사용하면 앞에 있는 내용을 모두 입력받아 , 일종의 치팅이 되기때문에 디코더만 사용하는것이 더 적절함
2. GPT-1에서는 Transformer의 Decoder 부분만을 사용 시, Cross Self Attention 부분은 제거한다.
- 🙆 Cross Self Attention 부분은 제거하는 이유는 ?
Transformer에서 Cross Self Attention은 Encoder의 입력과 Decoder의 입력 사이에서 발생해, Cross Attention 하는 역할. 하지만 GPT-1에서는 Encoder 없이 Decoder 단독으로 구성되었으니 Cross Attention 기능이 필요 없어짐. 대신 자기 어텐션(self-attention)만 사용하여 이전 단어들 간의 상호 작용을 캡처하고, 이를 바탕으로 다음 단어를 생성
⇒ GPT-1에서는 이렇게 Decoder 12개를 쌓아 올린 구조.
Decoder의 최종 Output에 Linear Layer와 Softmax를 이어주어 최종 Output Probability를 출력한다.
3-2. Unsupervised pre-training
- GPT-1의 Unsupervised Pre-Training 방법 => ⭐ GPT논문의 핵심
- BERT 등 다른 LLM들과 차별화되는 방법이며 근본적인 성능 차이를 가져오는 원인 중 하나
1. Next Word Prediction : 다음 단어를 맞추도록 학습
< Next Word Prediction 수식 >
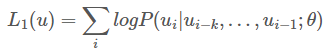

"Unsupervised Loss"는 GPT 모델과 같은 자기 지도 학습(Self-supervised learning) 기반의 모델에서 사용되는 손실 함수
모델이 사전 훈련된 데이터를 활용해 다음단어 예측하는 능력을 향상 시키는 목적. 즉, 이전 토큰들이 주어졌을 때 다음 토큰Ui 가 나올 확률이 최대가 되도록 파라미터를 학습함 예를 들어, “I love you” 라는 문장이 있을 때, (I, love)가 주어지면 you를 예측하는 확률값을 최대화
✅목적:
- 모델이 텍스트 시퀀스에서 다음 단어를 예측하는 능력을 향상
이를 통해 모델은 주어진 문맥에서 다음 단어를 정확하게 추론하고, 자연스러운 문장을 생성 - 자연어 처리 모델의 사전 훈련 단계에서 사용
텍스트의 구조와 패턴을 학습하여 모델이 특정 자연어 처리 작업에서 더 뛰어난 성능을 발휘할 수 있도록 도움
✅ 작동 원리:
- 텍스트 시퀀스에 대해 교차 엔트로피 손실(cross-entropy loss) (또는 유사 손실 함수 이용)을 이용해
모델이 예측한 다음 단어와 실제 다음 단어 간의 차이를 측정하여 계산 - 교차 엔트로피 손실은 모델이 예측한 확률 분포와 실제 레이블 간의 차이를 측정
- 모델은 이 손실을 최소화하도록 학습 → 훈련 과정에서 문맥을 이용하여 다음 단어를 예측하는 능력을 향상
[예시]
1) 전체 데이터셋은 아주 많은 문장으로 구성 → 데이터셋을 우선 문장별로 나누어준다
2) 각 문장을 GPT-1에 입력해주는데, 문장을 잘라서 주고 그 다음에 나올 단어를 예측하도록 학습
원문: "The cat sat on the mat."
모델 예측: "The cat sat on the mat." ( he cat sat on the 까지만 입력해주고 다음 문장예측하도록 학습)
실제 다음 단어: "mat"
✅효과 : GPT 시리즈는 모두 다음 단어를 예측하는 방식으로 학습하는 방법 사용 -> 왜 효과적일까?
1) 언어 구조를 학습
- 모델이 문장 내 단어 위치, 이후 어떤 단어가 올 확률이 높은지 등 언어의 기본적인 문법과 구조 자체를 이해
2) 문맥을 이해하는 능력 향상
3) 다양한 언어 패턴 학습
- Unlabeled Dataset
4) 전이 학습의 유용함
2) pre-training기법
Causal Language Modeling (CLM) 기법
- pre-training 방식에 사용되는 기법을 말하며 위와 같음
- 입력데이터와 출력데이터가 동일한 데이터를 가지고 있어서 사람이 따로 정답을 지정할 필요가 없음
- 입력데이터에는 BOS(begin of sentence) 토큰, 출력에는 마지막에 EOS(end of sentence) 토큰 이용
- 출력은 입력데이터에 대해 1만큼 offset
- loss function 수식위의 task의 학습 loss function을 수식으로 나타내면 다음과 같음
- t시점 이전의 토큰들과 모델을 이용하여 t시점의 토큰이 무엇인지 맞추는 형태로 loss가 구성됨
3. Supervised Fine-tuning
인풋토큰들에 대한 정답 레입르 y 필요 → 사전 훈련된 블록에 흘려줌 → 테스크마다 입력토큰들로부터 예측확률을 계산하여서 최종 output을 예측한다
문장 분류 작업으로 긍부정라벨링 →입력토큰은 x1,x2,x3갇된다 → 활성화값이 선현ㅇ레이어에 중비디어예측을 수행 가장 높은 확률을 가지는 클래스가 해당 문장의 예측결과가된다
Traversal-style approach - 데이터셋을 처
GPT
- fine - tuning 과정은 일반적은 supervised learning과 다르지 않음 → 단, 모델 초기 weights를 randomness하게 설정하는게 아니라 pre-trainging시에 학습한 모델을 weights로 하여 학습 진행
start BOS 토큰
| extract | EOS 토큰 |
| Text, Premise, Text1, Text2 등 보라색 | Special 토큰 |
| Trainsformer | Pre-training 된 GPT-1모델 |
⇒ 각 Task 별로 입력을 다르게 만들어서 학습을 진행해 Pre-training을 진행한 모델을 이용하면, fine-tuning시의 데이터가 적어도 좋은 성능을 보여줬음
[참고자료]
[2] GitHub - pilsung-kang/Text-Analytics: Unstructured Data Analysis (Graduate) @Korea University
[3] GPT-1(Generative Pre-Training) 원리 설명 [액션파워LAB] GPT-1(Generative Pre-Training) 알아보기



